Fiddler AI, a pioneer in AI observability and security for LLM and MLOps, has the mission of making the world a better place.
Following his session at Generative AI Summit Washington, D.C., I spoke with Nick Nolan, Solutions Engineering Manager at Fiddler AI, to dive into how they’re seeking to achieve this.
Q: Fiddler AI emphasizes building trust into AI systems. Can you elaborate on how your AI Observability platform achieves this, particularly concerning explainability and transparency?
Fiddler is the pioneer in AI observability and security for LLM and MLOps. Fiddler’s mission is to make the world a better place, as many of the decisions consumers make every day are influenced by AI.
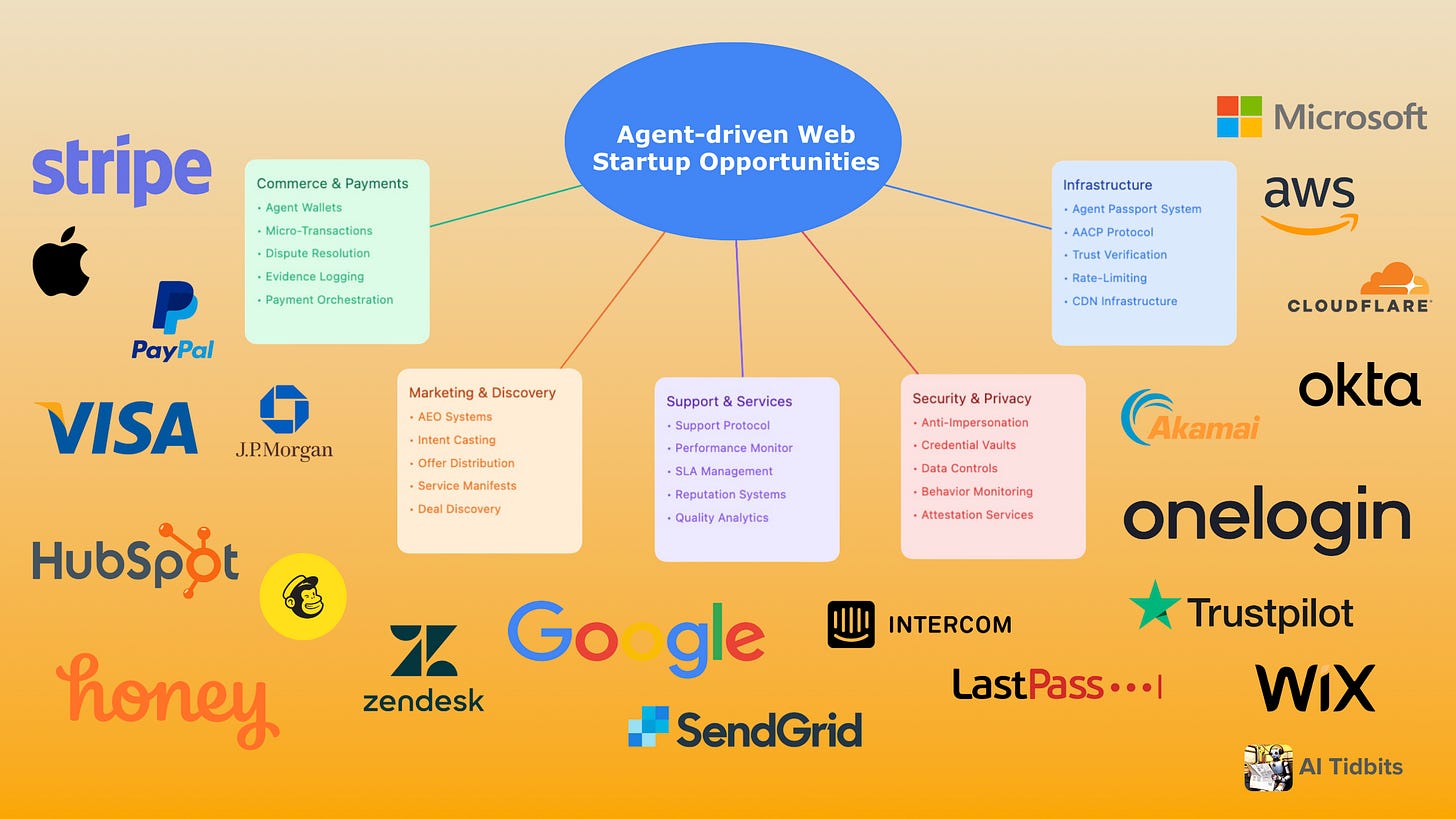
As AI continues to be deeply integrated into society, Fiddler addresses on two key areas:
1) Helping enterprise AI teams deliver responsible AI applications.
2) Ensuring that people interacting with AI receive fair, safe, and trustworthy responses.
As AI advances, particularly in generative AI, more policies will be introduced to enforce regulations around governance, risk, and compliance. These regulations will help enterprises strengthen oversight of their AI systems while protecting consumers from harmful, toxic, or biased outcomes.
We continue our mission to lead the way in helping enterprises deploy and use AI responsibly, ensuring trustworthy AI, and safeguarding consumers from harmful and unsafe outcomes. We support enterprises at every stage of their AI journey in establishing long-term responsible AI practices.From accelerating LLMOps and MLOps, driving business value, and mitigating risks to building customer satisfaction, we help establish responsible AI practices across all products as companies mature in their AI journey. Fiddler does so by supporting three key areas: monitoring, security and governance. We monitor a comprehensive set of LLM and ML metrics (performance, accuracy, drift, PII leakage, hallucination, safety, custom metrics), and if the metrics monitored go below a specific threshold, teams are alerted for immediate action using explainability and diagnostics for root cause analysis. Fiddler provides audit evidence and audit trail for regulatory and compliance reporting.
Q: With the rapid adoption of LLMs, what unique challenges do enterprises face in monitoring these models, and how does Fiddler’s LLM Observability address these
issues?
When GenAI emerged, companies rapidly began prompt engineering, fine-tuning, testing, and evaluating LLMs. This gave rise to numerous GenAI vendors specializing in pre-production testing and evaluation. However, LLM testing remains stuck in pre-production, neglecting the most challenging part: monitoring LLMs in real-world environments. Without oversight in production, enterprises risk hallucinations, safety concerns, and privacy breaches, harming users and the company. These risks limit their ability to explore AI innovation, keeping LLMs confined to testing environments.
The Fiddler Trust Service and its Guardrails solution help enterprises alleviate this issue. Fiddler Guardrails is the industry’s fastest guardrails with <100 ms response time, cost-effective, and can be securely deployed in the customers’ environment, VPC or air-gapped.
Customers use Fiddler to monitor LLM and ML metrics and link these metrics directly to their business KPIs, gaining valuable insights into how LLM and ML deployments impact business outcomes. This contributes to the ROI of positive business outcomes in several ways.
1. Fiddler enables the delivery of high-performance AI by allowing companies to launch and update models faster, leading to improved decision-making and revenue growth.
2. It reduces operational costs by accelerating the launch of AI applications, improving efficiency, identifying model issues, and minimizing downtime. The time savings for data science and ML engineers, who can monitor and debug models in minutes instead of weeks, boosts productivity.
3. Fiddler ensures responsible AI governance by minimizing reputational risks, reducing bias, and improving customer satisfaction, leading to higher Net Promoter Scores (NPS).
Q: The concept of Responsible AI is central to Fiddler’s mission. What strategies and tools do you provide to help organizations identify and mitigate biases in their AI models?
The Fiddler AI Observability and Security platform addresses bias through a comprehensive approach. Our platform continuously monitors models for bias and fairness issues across protected attributes, providing real-time alerts when models exhibit biased behavior. The platform’s explainability and model diagnostics capabilities deliver deep insights into model decision-making, enabling teams to perform detailed root cause analysis that uncovers the underlying factors contributing to bias. When issues are identified, Fiddler provides actionable insights for model and application improvement, allowing teams to implement targeted fixes rather than starting from scratch.
Beyond detection and mitigation, Fiddler supports responsible AI governance by automatically generating audit evidence for both internal reviews and external regulatory requirements. This documentation captures model behavior, fairness metrics, and mitigation efforts, helping organizations demonstrate compliance with governance, risk management, and compliance (GRC) standards. By integrating continuous monitoring, explainable AI, and robust governance capabilities, Fiddler transforms responsible AI from a theoretical goal into an operational reality.
Q: Could you share a case study where Fiddler’s platform significantly improved a client’s AI model performance or trustworthiness?
Integral Ad Science (IAS), a leader in Ad Tech, partnered with Fiddler to enhance the scope and speed of their digital ad measurement products while ensuring
compliance with AI regulations.
By using Fiddler’s AI Observability platform, IAS reduced monitoring costs, established rigorous oversight of their ML models, and improved collaboration with a unified view of model metrics. This enabled faster product launches, ensured compliance with regulatory standards, and provided audit evidence to stakeholders, all while promoting responsible AI practices through monitoring, explainability, and governance.
Full case study here.
Q: In the context of AI governance and compliance, how does Fiddler assist enterprises in meeting regulatory standards and ensuring ethical AI practices?
Fiddler helps enterprises navigate emerging regulations like the EU AI Act and AI Bill of Rights through three key capabilities.
First, we provide continuous monitoring of critical compliance metrics—tracking hallucinations, safety, and privacy in LLMs, while monitoring performance, accuracy, and drift in ML models.
Second, we automatically generate comprehensive audit evidence required for regulatory reviews and internal governance, crucial for enterprises’ compliance strategies.
Third, our platform enables ethical AI practices through specialized fairness monitoring that tracks intersectional bias across protected attributes. By integrating monitoring, documentation, and risk mitigation capabilities, Fiddler transforms compliance from a burden into a competitive advantage, helping companies innovate and build AI applications responsibly.
Q: As AI technologies evolve, how does Fiddler stay ahead in providing solutions that cater to emerging challenges in AI observability and security?
Fiddler stays ahead of emerging AI challenges through a combination of dedicated research, customer-driven innovation, and adaptive platform development. Our data science team leads AI research initiatives using research-based methodologies specifically designed to address real customer challenges in generative AI.
A prime example is our development of the Fiddler Trust Service, powered by proprietary Fiddler Trust Models. These fine-tuned, task-specific models form the foundation of our LLM solution, enabling LLM scoring, monitoring, and implementing effective guardrails. We’ve optimized the Fiddler Trust Models to deliver industry-leading guardrails with response times under 100 milliseconds, making it significantly faster than competing solutions.
Our approach prioritizes enterprise requirements, ensuring our solutions are not only powerful but also practical. The Fiddler Trust Models are designed to be cost-effective, minimizing the need for extensive inference or GPU resources that drive up operational costs. We’ve also built our platform with deployment flexibility in mind, allowing secure implementation within customers’ environments, including VPC or air-gapped deployments.
What distinguishes our research approach is its direct connection to customer needs. Rather than pursuing research for its own sake, we focus on solving specific challenges our enterprise customers face in deploying and managing AI systems. This customer-centric innovation model ensures our platform continuously evolves to address the most pressing real-world observability and security challenges in AI.
Q: Collaboration is key in the tech industry. Can you discuss any notable partnerships Fiddler has formed to enhance its platform’s capabilities?
Fiddler has established strategic partnerships with leading technology providers to create a comprehensive ecosystem that enhances our AI observability and security capabilities and extends our market reach.
Our collaboration with AWS includes deep integration with both Amazon SageMaker AI and Amazon Bedrock. The SageMaker AI integration enables customers to access Fiddler’s enterprise-grade AI observability directly within their existing MLOps workflows, eliminating additional security hurdles and accelerating the deployment of models into production. Our Amazon Bedrock integration extends these capabilities to LLM applications, allowing organizations to monitor and safeguard generative AI deployments with the same level of rigor.
We’ve also established a powerful partnership with NVIDIA that combines their NIM (NVIDIA Inference Microservices) and NeMo Guardrails with Fiddler’s observability and security platform. As a native integration to NVIDIA’s NeMo Guardrails orchestration platform, we provide the industry’s fastest guardrails with response times under 100 ms. This cost-effective and secure solution enables enterprises to deploy LLM applications at scale while effectively moderating conversations for hallucinations, safety violations, and jailbreak attempts. The integration allows prompts and responses processed by NIM to be automatically routed to Fiddler for guardrails and monitoring, providing comprehensive operational oversight.
Our partnership with Google Cloud has made the Fiddler AI Observability Platform available on Google Cloud Marketplace, providing seamless integration with Google Vertex AI and other Google Cloud AI offerings. This collaboration simplifies procurement through consolidated billing and allows customers to use pre-approved budgets for greater agility.
Additionally, we’ve partnered with Domino Data Lab to address the needs of government agencies deploying high-stakes AI systems. This collaboration enables agencies to develop models at scale with Domino while using Fiddler to validate model transparency, interpretability, and trustworthiness in production environments. These strategic partnerships and amongst others reflect our commitment to providing AI observability and security that integrates seamlessly with the broader AI ecosystem, helping organizations deploy responsible, accurate, and safe AI.
Q: How does Fiddler’s platform integrate with existing MLOps workflows, and what benefits does this integration bring to enterprise clients?
The Fiddler AI Observability and Security platform is designed with flexibility at its core, seamlessly integrating into customers’ existing tech infrastructure for both LLM and MLOps. Our fundamental goal is enabling enterprises to confidently ship LLM and ML applications into production where they can generate real business value.
For traditional MLOps workflows, Fiddler connects natively with ML platforms including Amazon SageMaker AI, Vertex AI, DataRobot, Domino, and homegrown ML systems. These integrations allow data science teams to monitor model performance, data drift, and fairness metrics without disrupting their established development environments. Our platform also plugs directly into enterprise data infrastructure like Google BigQuery, Databricks, Snowflake, Azure Data Lake, and Amazon S3, enabling efficient data flow between systems.
For LLM applications, Fiddler provides specialized integrations with generative AI frameworks and platforms. We integrate with gateway frameworks like NVIDIA NIM, Portkey, and custom solutions to monitor prompt-response interactions. Our connections to Gen AI platforms including Amazon Bedrock, NVIDIA NeMo, and Together.ai enable comprehensive LLM monitoring for hallucination rates, safety violations, and response quality.
What sets Fiddler apart is our adaptability to customers’ unique environments. Rather than forcing organizations to change their workflows or technology stacks, our solution is designed to be flexible for seamless implementation and accelerates time-to-value, allowing enterprises to move AI projects from experimentation to production more quickly and with greater confidence.
This flexible integration strategy delivers significant benefits:
1. Reduced barriers to production deployment by providing the monitoring, protection, and governance capabilities needed to satisfy stakeholders.
2. Accelerated value realization from AI investments by enabling faster, more confident production releases.
3. Unified visibility across heterogeneous AI environments spanning both traditional ML and LLMs.
4. Enhanced collaboration between security, AI application engineers, data science teams, ML engineers, and business stakeholders.
5. Lower total cost of ownership by eliminating the need for separate monitoring solutions for different model types.
By adapting to customers’ environments rather than forcing them to adapt to us, Fiddler helps enterprises transform AI from promising experiments into production systems that deliver measurable business impact.
Q: With the increasing focus on data privacy, how does Fiddler ensure that its AI observability tools align with data protection regulations?
Fiddler’s approach to data privacy and protection is built on a comprehensive security framework designed specifically for enterprise AI deployments. We’ve implemented robust measures to ensure our observability platform aligns with stringent data protection regulations while providing the insights organizations need.
Our multi-layered security architecture begins with sophisticated access controls. We implement Role-Based Access Controls (RBAC) that provide granular authorizations, ensuring that only authorized personnel can access specific data and functionality. This capability is particularly important for organizations with complex teams and governance requirements.
For data protection, we employ industry-leading encryption standards. All communications with and within customer clusters use HTTPS/TLS 1.2 (or higher), while data-at-rest is secured with AES-256 key encryption. We maintain daily backups of encrypted customer data and implement secure deletion procedures at the end of retention periods to prevent unauthorized access to historical information.
Our commitment to compliance is demonstrated through SOC2 certification and HIPAA compliance, validating our security practices against recognized industry standards. Security is integrated throughout our software development lifecycle, with rigorous controls including security design reviews, threat modeling, application security scans, container image scanning, and network monitoring.
Importantly, Fiddler’s platform architecture respects data sovereignty principles – customer data remains within their premises, never leaving their controlled environment. This architecture is crucial for organizations operating under regulations like GDPR that have strict requirements about data movement and storage.
For AI-specific challenges, our platform provides specialized capabilities to detect potential privacy issues in model behavior. We generate comprehensive metrics after model registration to help identify concept drift, data leakage, and other anomalies that might indicate privacy vulnerabilities. These monitoring capabilities allow organizations to detect and respond to issues before they result in regulatory violations.
By combining these technical safeguards with our privacy-by-design philosophy, Fiddler ensures that organizations can implement robust AI observability and security while maintaining full compliance with data protection regulations.
Q: Looking ahead, what are Fiddler AI’s strategic priorities for the next five years in advancing AI observability and fostering responsible AI adoption?
Fiddler’s five-year strategy centers on expanding our AI observability leadership while enabling enterprises to deploy responsible AI at scale. Building on our 2024 launch of the Fiddler Trust Service — the industry’s first comprehensive solution for LLM scoring that enables LLM monitoring and powers the industry’s fastest, cost-effective guardrails with <100 ms response time — we’re focused on addressing increasingly complex AI ecosystems.
We’re developing enhanced capabilities for agentic AI systems through advanced tracing features like Traces and Spans, providing granular insights for complex application architectures. Our roadmap emphasizes customer-driven innovation, with continued research into optimizing AI systems for performance, cost-effectiveness, and security to ensure all stakeholders experience responsible, equitable, and accurate AI.
We’re also investing in making responsible AI more accessible through educational resources and simplified implementation frameworks. This democratization effort will help organizations at all AI maturity levels implement effective governance without impeding innovation. Throughout these initiatives, we’ll maintain our focus on helping customers extract measurable business value from their AI investments, transforming promising experiments into mission-critical AI systems that deliver tangible results while upholding the highest ethical standards.
Our ultimate goal remains enabling enterprises to confidently deploy AI that generates real business value while ensuring that everyone—enterprises, employees, and end-users alike—benefits from AI that is responsible, equitable, and safe.