What makes something an “AI agent” – and how do you build one that does more than just sound impressive in a demo?
I’m Nico Finelli, Founding Go-To-Market Member at Vellum. Starting in machine learning, I’ve consulted for Fortune 500s, worked at Weights & Biases during the LLM boom, and now I help companies get from experimentation to production with LLMs, faster and smarter.
In this article, I’ll unpack what AI agents actually are (and aren’t), how to build them step by step, and what separates teams that ship real value from those that stall out in proof-of-concept purgatory.
We’ll also take a close look at the current state of AI adoption, the biggest challenges teams face today, and the one thing that makes or breaks an agent system: evaluation.
Let’s dive in.
Where we are in the AI landscape
At Vellum, we recently partnered with Weaviate and LlamaIndex to run a survey of over 1,200 AI developers. The goal? To understand where people are when it comes to deploying AI in production.
What we found was pretty surprising: only 25% of respondents said they were live in production with their AI initiative. For all the hype around generative AI, most teams are still stuck in experimentation mode.
The biggest blocker? Hallucinations and prompt management. Over 57% of respondents said hallucinations were their number one challenge. And here’s the kicker: when we cross-referenced that with how people were evaluating their systems, we noticed a pattern.
The same folks struggling with hallucinations were the ones relying heavily on manual testing or user feedback as their main form of evaluation.
That tells me there’s a deeper issue here. If your evaluation process isn’t robust, hallucinations will sneak through. And most businesses don’t have automated testing pipelines yet, because AI applications tend to be highly specific to their use cases. So, the old rules of software QA don’t fully apply.
Bottom line: without evaluation, your AI won’t reach production. And if it does, it won’t last long.
So, how are the companies that do get to production pulling it off?
First, they don’t just chase the latest shiny AI trend. They start with a clearly defined use case and understand what not to build. That discipline creates focus and prevents scope creep.
Second, they build fast feedback loops between software engineers, product managers, and subject matter experts. We see too many teams build something in isolation, hand it off, get delayed feedback, and then go back to the drawing board. That slows everything down.
The successful teams? They involve everyone from day one. They co-develop prompts, run tests together, and iterate continuously. About 65–70% of Vellum customers have AI in production, and these fast iteration cycles are a big reason why.
They also treat evaluation as their top priority. Whether that’s manual review, LLM-as-a-judge, or golden datasets, they don’t rely on vibes. They test, monitor, and optimize like it’s a software product – because it is.
According to recent Cisco research, it’s projected that by 2028, 68% of all customer service and support interactions with tech vendors will be handled by agentic AI. This makes sense, as 93% of respondents in the same study predict that a more personalized, predictive, and proactive service will be possible with agentic AI.
Agentic AI represents a departure from traditional automation, as it enables AI agents to act independently, make decisions with minimal human input, and learn from context. Earlier systems required humans to connect and monitor the automated workflows. However, agentic AI agents have reasoning abilities, memory, and task awareness.
Because agentic AI can enhance both the operation and management of interconnected devices, this development is particularly relevant to the IoT (Internet of Things). It can proactively address network issues that originate from misconfigurations, which results in stronger security, smarter networks, and more productive teams.
Agentic AI introduces an essential shift in how intelligent systems are architected and deployed, transitioning from task-specific and supervised models to autonomous and goal-oriented agents that can make real-time decisions and adapt to their environment.
Intelligence is mainly static and narrowly scoped in traditional AI systems; models are trained offline and embedded into rule-based workflows, usually operating in a reactive way. A conventional AI system could, for example, classify network anomalies or trigger alerts, but still rely on humans to contextualize signals and respond.
Agentic AI systems, however, are formed of AI agents that have agency:
Memory. Continuous internal state across interactions and tasks.
Autonomy. Ability to plan, execute, and adapt strategies without needing real-time human input.
Task awareness. An understanding of task objectives, dependencies, and sub-task decomposition.
Learning and reasoning. Ability to infer causality and change behavior depending on data and environmental signals.
As these agents have intention-driven behavior, they can decide how to perform a task, and which task to undertake based on system-level goals. Agentic AI systems often employ multi-agent coordination, where distributed agents communicate, negotiate, and delegate tasks across a network, which is ideal for large-scale and latency-sensitive environments, such as the Internet of Things (IoT).
Taking an industrial IoT context, a traditional AI pipeline would:
Detect vibration anomalies in a turbine,
Flag it for a technician via a dashboard,
And wait for human triage.
In contrast, an agentic AI system would:
Detect the anomaly in the turbine,
Query contextual data (such as usage patterns),
Dispatch a robot or an autonomous drone to inspect the anomaly,
Adjust the operating parameters of any adjacent machinery,
Alert a technician only after composing a full incident report and proposing actions.
Taking IoT into consideration, agentic AI eliminates the need for centralized control and brittle scripting. Instead, it promotes systems capable of evolving and optimizing over time, which is essential for those dynamic environments where resilience, latency, and scalability are crucial.
Why agentic AI matters for IoT
The intersection between agentic AI and IoT is a vital issue in distributed computing. IoT systems are becoming increasingly dense and latency-sensitive, and traditional centralized or rule-based automation is struggling to scale. Agentic AI is the solution to this challenge, allowing for decentralized and real-time decision-making at the edge.
Agentic systems work as goal-oriented and persistent software agents that are capable of adaptive planning, context retention, and multi-agent coordination. When they’re deployed across IoT networks, like cities, smart homes, or factories, AI agents allow for dynamic and autonomous orchestration of device behaviors and inter-device logic.
Smart homes
Agentic agents are able to autonomously manage demand-side energy consumption by dynamically adjusting lighting, HVAC, and storage systems based on real-time information and historical usage.
Smart cities
Agents can manage distributed load balancing across the infrastructure in municipal contexts. They dynamically re-route traffic through real-time edge sensor inputs or by coordinating energy resources through microgrids and public utilities, according to forecasted demand.
Industrial IoT
Agentic AI allows for runtime decisioning in factory or logistics networks for quality control, maintenance, and asset reallocation. If an agent embedded in a vibration sensor detects abnormal patterns, it can issue localized shutdowns while updating a model used by agents in adjacent systems.
IBM ATOM (Autonomous Threat Operations Machine) is a system created to enhance cybersecurity operations through the use of agentic AI. It works by orchestrating multiple specialized AI agents that collaborate to detect, investigate, and respond to security threats with minimal human intervention.
Abdelrahman Elewah and Khalid Elgazzar developed the IoT Agentic Search Engine (IoT-ASE) to address the challenges of fragmented IoT systems. These often impede seamless data sharing and coordinated management. By leveraging large language models (LLMs) and retrieval augmented generation (RAG) techniques, IoT-ASE can process large amounts of real-time IoT data.
Challenges and opportunities
With the increasing presence of agentic AI systems across IoT environments, several technical challenges need to be addressed. Edge computing still has limitations that create a critical challenge. Agents thrive on local autonomy, but many edge devices still don’t have enough compute power, energy efficiency, or memory to support complex and context-aware reasoning models under real-time constraints.
There are also trust and privacy concerns. Agents operate semi-independently, meaning that their decision-making has to be auditable and aligned with both security and data governance policies. Any agent hallucinations or misaligned goals can lead to real-world risks, particularly in safety-critical environments.
Inter-agent communication and communication is another challenge that needs to be addressed. Strong communication protocols and semantic interoperability are needed so that agents don’t become brittle or inefficient in collaborative tasks.
These challenges can, however, point to some opportunities. Developing open standards for agent behavior, audit traits, and coordination could lead to ecosystem-level interoperability. Feedback loops, task routing, and dynamic oversight are frameworks for human-agent collaboration that can blend human judgment with scalable automation.
Why this matters now
This convergence of agentic AI and IoT is happening in real-time. Organizations are pushing to deploy more intelligence and distributed systems, and the need for autonomous and goal-driven agents is an architectural need.
That’s why events like the Agentic AI Summit New York are so important. They offer a platform to showcase innovation and to confront the practical infrastructure, coordination, and safety challenges that exist with large-scale agentic deployments.
Co-located alongside the Generative AI Summit and the Chief AI Officer Summit, this event forms part of a broader conversation on how intelligence is being embedded not just at the system level, but also into leadership strategy and foundational model development—making it a key gathering point for those shaping the future of AI in all its forms.
As the convergence of agentic AI and IoT accelerates, keeping pace with how the ecosystem evolves is more important than ever. Platforms likeIoT Global Network offer a window into the technologies, use cases, and players shaping this space.
Advanced AI and NLP applications are in great demand in today’s modern world, wherein most businesses rely on data-driven insights and automation of business processes.
All applications of AI or NLP have a requirement for a data pipeline that can ingest data, process it, and provide output for training, inference, and subsequent decision making at a large scale. AWS is taken to be the cloud standard with its scalability and efficiency for building these pipelines.
In this article, we will discuss designing a high-performance data pipeline using only basic AWS services like Amazon S3, AWS Lambda, AWS Glue, and Amazon SageMaker for AI and NLP applications.
This article discusses building a high-performance data pipeline for AI and NLP applications using core AWS services such as Amazon S3, AWS Lambda, AWS Glue, and Amazon SageMaker.
Why AWS for data pipelines?
AWS is the most preferred choice for building data pipelines because of its strong infrastructure, rich service ecosystem, and seamless integration with ML and NLP workflows. Azure, Google Cloud, and AWS also outperform open source tools like Apache Suite in terms of ease of use, operational reliability, and integration. Some of the benefits of using AWS are:
Scalability
AWS would automatically scale up or down because of its elasticity, hence always assuring high performance irrespective of the volume of data. Though Azure and Google Cloud provide features for scaling, the auto-scaling options available in AWS are more granular and customizable, hence providing finer control over resources and costs.
Flexibility and integration
AWS has various services that best fit the components of a data pipeline, including Amazon S3 for storage, AWS Glue for ETL, and Amazon Redshift for data warehousing. More so, seamless integrations with AWS ML services like Amazon SageMaker and NLP models make it perfect for AI-driven applications.
Cost efficiency
AWS’s pay-as-you-go pricing model ensures cost-effectiveness for businesses of all sizes. Unlike Google Cloud, which sometimes has a higher cost for similar services, AWS provides transparent and predictable pricing. Reserved Instances and Savings Plans further enable long-term cost optimization.
Reliability and global reach
AWS is built on extensive global infrastructure comprising several data centers across the world’s regions, ensuring high availability and low latency for users spread worldwide.
Whereas Azure also commands a formidable presence around the world, the sheer reliability and experience in operations favor AWS. AWS, moreover, provides compliance with a broad set of regulatory standards and hence finds a better proposition in healthcare and finance.
Security and governance
AWS provides default security features, including encryption, identity management, and more, to keep your data safe during the entire data pipeline. AWS provides AWS Audit Manager and AWS Artifact for maintaining compliance-much more advanced compared to what is available on other platforms.
So, by choosing AWS, organizations gain access to a scalable and reliable platform that simplifies the process of building, maintaining, and optimizing data pipelines. Its rich feature set, global reach, and advanced AI/ML integration make it a superior choice for both traditional and modern data workflows.
Before discussing architecture, it is worth listing some key AWS services that almost always form part of a data pipeline for artificial intelligence or NLP applications:
Amazon S3 (Simple Storage Service): A kind of object storage that can scale to hold enormous amounts of unstructured data. In general, S3 acts like an entry point or an ingestion layer where raw datasets are normally stored.
Amazon Kinesis: A service for real-time data streaming, allowing ingesting and processing streams of data in real time. Applications requiring live data analysis can apply this.
AWS Lambda: A serverless compute service that allows you to run code without provisioning servers. Lambda is very helpful in event-driven tasks, for example: data transformation or triggering a workflow when newer data arrives.
AWS Glue: A fully managed extract, transform, and load (ETL) service that prepares and transforms data automatically for analysis. Glue can also act as a catalog for locating and organizing the data stored within various AWS services.
Amazon SageMaker: This is Amazon’s fully integrated service of machine learning, which greatly simplifies the process through which developers build, train, and deploy AI models. SageMaker works in conjunction with other AWS data pipeline services, providing an easier way to operationalize AI and NLP applications. As a result, it has become much easier for developers, scientists, and engineers to build integrated AI and NLP applications through SageMaker’s single-click workflows.
Designing an efficient data pipeline for AI and NLP
A structured approach is paramount in designing a really efficient data pipeline for AI/NLP applications. Further below are steps regarding how an effective pipeline can be designed on AWS.
Step 1: Ingesting data
Normally, the ingestion of data is the first activity in any data pipeline. AWS supports various methods of data ingesting, depending on the source and nature of the data.
In general, data can be unstructured, like text, images, or audio, for example. In that case, it usually would have Amazon S3 as a starting point for data storage. On the other side, Amazon Kinesis would work just fine for real-time data ingesting that may emanate from sensors, social media, or streaming platforms.
Most of the time, this is something that forms a starting point of your big data pipeline, tasked with collecting and processing huge amounts of data in real time before sending it further down the pipeline.
Step 2: Data transformation and preparation
Once ingested, the data should be prepared and transformed into a format appropriate for AI and NLP models. AWS has the following tools for this purpose:
AWS Glue: It is the ETL service that makes the process of data extraction from one storage to another much smoother and straightforward.
In cleaning and preprocessing text data as preparation for several NLP tasks, such as tokenization, sentiment analysis, or entity extraction, this tool can be applied. AWS Lambda is another very useful tool for performing event-driven transformations.
The latter automatically preprocesses data in S3 for newly uploaded objects, which could mean filtering, format conversion, or enriching with additional metadata. Several applications of AI in real-time prediction can be directly fed into Amazon SageMaker for training or inference.
Running the batch jobs periodically through the scheduling of AWS Glue and Lambdas will ensure that data is always up to date.
Step 3: Model training and inference
Following data preparation, this is where the actual training of AI and NLP models happens. Amazon SageMaker is a comprehensive environment for machine learning to rapidly build, train, and deploy models.
Thus, one can now use SageMaker in this regard to support popular ML frameworks like TensorFlow, PyTorch, and scikit-learn, which directly integrates with S3 for access to the training data.
Similar to specific tasks involving NLP, such as sentiment analysis, machine translation, and named entity recognition, there is a built-in solution within SageMaker for natural language processing. Seamlessly train your NLP models on SageMaker and scale up the training on several instances for faster performance.
Finally, SageMaker deploys the trained model to an endpoint that can then be used to make predictions in real time. These results can then be written back to S3 or even to a streaming service like Amazon Kinesis Data Streams for further processing.
Step 4: Monitoring and optimization
The proper workflow is to keep a check on the performance-security of both the data pipeline and the models. AWS provides some sets of monitoring tools, such as Amazon CloudWatch, to track metrics, log errors, and trigger alarms in case of something wrong happening with the pipeline.
You can also use Amazon SageMaker Debugger and Amazon SageMaker Model Monitor to monitor the performance of ML models in production. These allow you to detect anomalies, monitor for concept drift, and otherwise make sure your model keeps performing as expected over time.
Step 5: Integrating with data analytics for fast query and exploration
Once your data pipeline is processing and producing outputs, enabling efficient querying and exploration is key to actionable insights. This ensures not only that your data is available but also accessible in a form that allows for rapid analysis and decision-making.
AWS provides robust tools to integrate analytics capabilities directly into the pipeline:
Amazon OpenSearch Service: to offer full-text search, data visualization, and fast querying over large datasets, something important, especially when analyzing logs or results originating from NLP tasks.
Amazon Redshift: Run complex analytics queries on structured data at scale. Redshift’s powerful SQL capabilities allow seamless exploration of processed datasets, enabling deeper insights and data-driven decisions.
This integration pipes the transformed data out to immediate exploration in real-time and/or to downstream analytics, giving a complete view of outputs from your pipeline, which brings us to the next section, where we’ll explore best practices for building efficient and scalable AWS data pipelines.
You can do this by using AWS Lambda and AWS Glue to simplify your architecture by reducing the overhead involved in the management of servers. In that respect, a serverless architecture will ensure that your pipeline scales seamlessly, utilizing only those resources actually used. Thus, it becomes optimized for performance and cost.
Automate data processing
Leverage event-driven services like AWS Lambda to have events triggered automatically for the transformation and processing of incoming data. This ensures minimum human intervention and that the pipeline is up and running smooth, without delays.
Utilize different storage classes in Amazon S3, such as S3 Standard, S3 Infrequent Access, and S3 Glacier, to balance cost and access needs. For infrequently accessed data, use Amazon S3 Glacier to store the data at a lower cost while ensuring that it’s still retrievable when necessary.
Implement skey
Ensure that your data pipeline adheres to security and compliance standards by using AWS Identity and Access Management (IAM) for role-based access control, encrypting data at rest with AWS Key Management Service (KMS), and monitoring network traffic with AWS CloudTrail.
Security and compliance are key in AWS data pipelines, considering the present landscape where data breaches are rampant, coupled with growing regulatory scrutiny.
Therefore, this may involve sensitive information such as personally identifiable information, financial records, or healthcare data that demands strong security measures against unauthorized access to protect against possible monetary or reputational damage.
AWS KMS ensures data at rest is encrypted, making it unreadable even if compromised, while AWS IAM enforces role-based access to restrict data access to authorized personnel only, reducing the risk of insider threats.
Compliance with regulations like GDPR, HIPAA, and CCPA is crucial for avoiding fines and legal complications, while tools like AWS CloudTrail help track pipeline activities, enabling quick detection and response to unauthorized access or anomalies.
Beyond legal requirements, secure pipelines foster customer trust by showcasing responsible data management and preventing breaches that could disrupt operations. A robust security framework also supports scalability, keeping pipelines resilient and protected against evolving threats as they grow.
It is important to keep prioritizing security and compliance so that organizations not only safeguard data but also enhance operational integrity and strengthen customer confidence.
Conclusion
AWS is a strong choice for building AI and NLP data pipelines primarily because of its intuitive user interface, robust infrastructure, and comprehensive service offerings.
Services like Amazon S3, AWS Lambda, and Amazon SageMaker simplify the development of scalable pipelines, while AWS Glue streamlines data transformation and orchestration. AWS’s customer support and extensive documentation further enhance its appeal, making it relatively quick and easy to set up pipelines.
To advance further, organizations can explore integrating AWS services like Amazon Neptune for graph-based data models, ideal for recommendation systems and relationship-focused AI.
For advanced AI capabilities, leveraging Amazon Forecast for predictive analytics or Amazon Rekognition for image and video analysis can open new possibilities. Engaging with AWS Partner Network (APN) solutions can also offer tailored tools to optimize unique AI and NLP workflows.
By continuously iterating on architecture and using AWS’s latest innovations, businesses can remain competitive while unlocking the full potential of their data pipelines.
However, AWS may not always be the best option depending on specific needs, such as cost constraints, highly specialized requirements, or multi-cloud strategies. While its infrastructure is robust, exploring alternatives like Google Cloud or Azure can sometimes yield better solutions for niche use cases or integration with existing ecosystems.
To maximize AWS’s strengths, organizations can leverage its simplicity and rich service catalog to build effective pipelines while remaining open to hybrid or alternative setups when business goals demand it.
Although AI has been the No. 1 trend since at least 2023, organizational AI governance is just slowly catching up.
But with rising AI incidents and new AI regulations, like the EU AI Act, it’s clear that an AI system that is not governed appropriately has the potential to cause substantial financial and reputational damage to a company.
In this article, we explore the benefits of AI governance, its key components, and best practices for minimal overhead and maximal trust. Additionally, we cover two cases of how to start building an AI governance, demonstrating how a dedicated AI governance tool can be the game changer.
Summary
Efficient AI governance mitigates financial and reputational risks through fostering responsible and safe AI.
Key components of AI governance include clear structures and processes to control and enable AI use. An AI management system, a risk management system, and an AI registry are part of that.
Start governing AI in your organization by implementing a suitable framework, collecting your AI use cases, and mapping the right requirements and controls to the AI use case.
The EU AI Act poses additional compliance risks due to hefty fines. AI governance tools can help in creating compliance, e.g. by mapping of the respective requirements to your AI use cases and automated processes.
When selecting a dedicated AI governance tool, look beyond traditional GRC functionalities, but for curated AI governance frameworks, integrated AI use case management, and the connection to development processes or even MLOps tools. This is part of our mission at trail. </aside>
A lack of effective AI governance can lead to severe AI incidents that can create physical or financial harm, reputational damage, or negative social impact. For instance, Zillow, a real estate company,suffered a $304 million loss and had to lay off 25% of its staff due to incorrectly predicted home prices, causing the company to overpay for purchases, relying on suggestions by AI models.
Similarly, Air Canada was facingfinancial losses stemming from a court ruling triggered by a chatbot’s wrong responses regarding the company’s bereavement rate policy.
These incidents highlight the importance of having AI governance measures in place, not just for ethical reasons, but to protect your business from avoidable harm. The demand for effective governance structures, safety nets, and responsible AI has been increasing drastically in the past months.
Companies, especially large enterprises, can only scale AI use cases when ensuring trustworthiness, safety, and compliance throughout the AI lifecycle.
However, AI governance is often perceived as slowing down performance and decision-making, as additional structures, policies, and processes can create manual overhead. But when implemented in an efficient and actionable manner, AI governance structures accelerate innovation, create business intelligence, and reduce the risk of costly issues later on. Put differently: You can move fast without breaking things.
By now, there are already dedicated AI governance tools out there that can help you to automate compliance processes, for instance, the writing of documentation or finding the evidence needed to fulfil your requirements.
But they also help you to bring structure to your AI governance program and curate best practices for you. As AI continues to reshape businesses, robust and automated governance practices will be the cornerstone of responsible AI adoption at scale.
At trail, we developed a process with actionable steps and specific documents you can request here to jump-start your strategy.
But what exactly is AI governance? AI governance is a structured approach to ensure AI systems work as intended, comply with the rules, and are non-harmful. It’s much more than classical compliance, though, as it tries to put the principles of responsible AI, such as fairness or transparency, into practice.
Some key components include:
Clear management structures, roles, and responsibilities
A systematic approach to development or procurement processes, fulfilling requirements and meeting controls (that includes risk management, quality management, and testing)
AI principles implemented in a company-wide AI policy with C-level support
AI registry as an inventory of all AI use cases and systems
AI impact assessments
Continuous monitoring (and audits) ofan AI system’s performance
Mechanisms to report to all relevant stakeholders
It’s becoming clear that companies’ focus is shifting — from “if” to “how” when it comes to AI governance implementation. Especially with the EU AI Act coming into force in August 2024 and first deadlines having already passed, it transitioned from a pioneering effort to a non-negotiable when scaling AI in the enterprise.
When starting to think about how to set up your AI governance program, it can make sense to start with your legal requirements and to tackle compliance challenges first.
This is because non-compliance can come with hefty fines, as seen in the EU AI Act, for instance, and it could open the door for discussions about responsible AI in your organization. However, it is important not to think of AI governance as merely a compliance program.
As regulatory compliance in itself can become quite complex, automated AI governance structures that cover e.g. EU AI Act provisions and that facilitate the categorization of AI systems will free up the resources needed for important innovation.
The EU AI Act 🇪🇺
The EU AI Act is the first comprehensive regulation on AI, aiming to ensure that AI systems used in the EU are safe, transparent, and aligned with fundamental rights. Non-compliance can result in penalties up to 35 Mio. EUR or 7% of the global turnover, whichever is higher.
Put in simple terms, it categorizes AI systems into four risk levels: unacceptable, high, limited, and minimal risk.
Unacceptable risk systems—like social scoring or real-time biometric surveillance—are banned entirely.
High-risk systems, such as HR candidate analyses, credit scoring, or safety components in critical infrastructure, must meet strict requirements, including risk management, transparency, human oversight, and detailed technical documentation.
Limited-risk systems, or those with a “certain risk” (e.g. chatbots interacting with humans) require basic transparency measures, and minimal-risk systems face no further obligations.
General-purpose AI (GPAI) models, like large language models, are covered separately under the Act, with dedicated obligations depending on whether the model is classified as a foundational GPAI or a high-impact GPAI, focusing on transparency, documentation, and systemic risk mitigation.
The requirements organizations face can differ on an AI use case basis. To identify the respective requirements, one must consider the risk class and role (such as provider, deployer, importer, or distributor) of the use case under the AI Act.
A transparent inventory of all AI use cases in the organization enables the categorization and lays the first step towards compliance. However, even if AI use cases across the organization are not accompanied by extensive requirements, implementing AI governance practices can speed up innovation and position an organization at the forefront of responsible AI practices.
But how can a company implement AI governance effectively?
The answer to this question is dependent on the status quo of the organization’s AI efforts and governance structures.
If no governance processes or even AI use cases have been established, the organization can fully capitalize on a greenfield approach and build up a holistic AI governance from scratch. If there are already compliance structures in place, aligning such structures across departments that use AI is crucial to achieve some sort of standardization.
Additionally, established IT governance practices should be updated to match the dynamic nature of AI use cases. This can result in shifting from static spreadsheets and internal wiki pages to a more efficient and dynamic tooling that enables you to supervise AI governance tasks.
Working with many different organizations on setting up their AI governance in the past years has let us find common structures and best practices that we are covering in our starter program, “the AI Governance Bootcamp,” so you don’t have to start from scratch. Find more informationhere.
First steps for getting started with AI Governance:
Choosing a framework: Don’t reinvent the wheel — start with existing frameworks like EU AI Act, ISO/IEC 42001, or NIST AI Risk Management and align them with your organization. The next step is to translate the frameworks’ components into actionable steps that integrate into your workflows. This cumbersome procedure can be fast-tracked by using dedicated software solutions that already embed the frameworks and respective controls, while leaving enough room for you to customize where needed.
Collection of AI use cases: The next step is to collect existing AI use cases and evaluate them according to their impact and risk. If the AI Act is applicable to your organization, it must also be categorized according to the EU AI Act’s risk levels and role specifications. This AI registry also gives you a great overview of the status quo of past, current, and planned AI initiatives, and is usually the starting point for AI governance on the project level.
Using tools to streamline governance: When setting up AI governance or shifting from silos to centralized structures, a holistic AI governance tool can be of great benefit. While a tool in general can be helpful to reduce manual overhead through automation, it facilitates the tracking of requirements, collaboration, and out-of-the-box use of an AI registry and categorization logic. Additionally, tools, such as those bytrail, often already cover most of the AI governance frameworks, translate the (often vague) requirements into practical to-dos, and even automate some evidence collection processes.
Best practices for successful AI governance implementation
For AI governance to be as efficient as possible, some best practices can be deduced from pioneers in the field:
First and foremost, AI governance should not be just a structural change, but should always be accompanied by leadership and cultural commitment. This includes both the active support of ethical AI principles, but it can also shape an organization’s vision and brand.
This can be best achieved if the entire company is invested in responsible AI and involved with the required practices. Start by showing C-level support through executive thought leadership and assigning clear roles and responsibilities.
Additionally, having an AI policy is a crucial step to building a binding framework that supports the use of AI. The AI policy outlines which AI systems are permitted or prohibited to use, and which responsibilities every single employee has, e.g. in case of AI incidents or violations.
Another key driver for successful AI governance implementation is the ability to continuously monitor and manage the risks of AI systems. This means having regular risk assessments and implementing a system that can trigger alerts when passing certain risk and performance thresholds, and when incidents occur. Combining this with risk mitigation measures and appropriate controls ensures effective treatment.
Involving different stakeholders in the design and implementation process can greatly help to gather important feedback, but also includes providing ongoing training programs for all stakeholders to ensure AI literacy and promote a culture of transparency and accountability.
Real-world examples
To help you understand where to begin, we’re sharing two real-world client examples tailored to different stages of organizational maturity. One shows how we helped a client build AI governance from the ground up. The other highlights how we scaled AI governance within a highly regulated industry.
1.) The SME: Innovation consulting firm for startups and corporates
Our first client is an innovation consultancy for startups and mostly mid-cap corporates. Their processes need to be dynamic and fast, and should not block their limited human resources, with about 400–500 employees. As they did not have any AI governance structures in place and a small legal team, we’ve helped them to create their governance processes from scratch.
We focused on three main aspects: building up an AI policy, fostering AI literacy to comply with Article 4 of the EU AI Act, and setting up an AI registry with respective governance frameworks and workflows. All of this was conducted via our AI governance tool trail.
Especially the AI training, which was implemented by their HR, was a central part in enabling the workforce to leverage their new AI tools effectively. Building up the AI registry laid the foundation for transparency about all permitted AI use cases in the company, and is now used as the starting point for their EU AI Act compliance process per use case.
2.) The enterprise: IT in finance
Our second client example is a company operating in the financial industry with 5000+ employees. This firm already had lots of existing risk management and IT governance processes that were scattered across the organization,e.g. and several AI initiatives and products.
Together with a consultancy partner who was actively contributing to the change management, we started to aggregate processes to find an efficient solution for AI governance. We started by assessing the status quo with a comprehensive gap analysis of their governance structures and AI development practices.
This allowed us to pinpoint areas in need of adjustment or missing components, e.g., EU AI Act compliance. Stakeholder mapping and management is an essential part when distributing responsibilities of governance and oversight — this requires a lot of time.
In the next step, we built up an AI registry via the trail platform to have a single source of truth on what AI systems and use cases exist. The main challenge was the identification of these, as they were scattered across internal wiki pages and multiple IT asset inventories. Finally, this enabled us to classify all AI use cases and to connect them to the respective governance requirements, starting with the EU AI Act requirements.
In-house developed AI systems, in particular, require thorough documentation, which creates manual overhead for developers and other technical teams.
Therefore, technical documentation is being created using trail’s automated documentation engine, which gathers the needed evidence directly from code via its Python package and creates documentation using LLMs.
This helps to automatically track the relevant technical metrics and directly recycle them into documentation. This decreases the manual overhead drastically and increases the quality of documentation and citation.
As this client already had an established organization-wide risk management process, it was essential to integrate the management of AI-related risks into their existing process and tool. By integrating an extensive AI risk library and respective controls from trail, a dedicated process of risk identification and mitigation for AI could be established and fed into the existing process.
After starting to work with trail, our client was able to speed up processes, increase transparency, embed a clear AI governance structure, and save time with more efficient documentation generation. This positioned them as a pioneer of responsible AI among their clients and allowed for in-time preparation for the EU AI Act.
What to look for in governance tools
Especially the latter case shows how clever solutions are necessary in order to balance innovation and compliance when existing governance structures are not uniform.
As AI governance is evolving, traditional tools like spreadsheets no longer meet the complexity or pace of modern compliance needs. And rather than viewing regulation as a roadblock, teams should embed governance directly into their development workflows to speed up innovation processes by streamlining documentation, experimentation, and stakeholder engagement.
However, not every GRC tool is a good fit for AI governance. Here are some key features every efficient AI governance tool should have:
Curated governance frameworks: A good AI governance tool should offer a library of different governance frameworks, AI-related risks and controls, and automate the guidelines or requirements as much as possible. Such frameworks can either be ethical guidelines or include regulations like the EU AI Act or certifiable standards such as ISO/IEC 42001. Some tasks and requirements cannot be automated, but a tool should give you the guidance to complete and meet them efficiently.
AI use case management: A governance tool that helps you to manage AI use cases and depict your AI use case ideation process, not only supports you in thinking about governance requirements early on. It also allows you to make AI governance the enabler of AI innovation and business intelligence by having a central place to oversee how individual teams make use of AI in your company. From here, each stakeholder can see the information relevant to them and start their workflows. The AI registry is a must-have even for those who are less concerned with governance. Why not make it multipurpose?
Connection to developer environments: An effective tool lets you think about AI governance holistically and across the whole AI life cycle. This means that you need to integrate with the developer environments. By using a developer-friendly governance tool, you can directly extract valuable information from the code and data to automate the collection of evidence and create documentation. Further, it can also show you which tasks must be done during development already to achieve compliance and quality early on.
An example of such a tool, enabling effective AI governance, is the trail ****AI Governance Copilot. It’s designed for teams that want to scale AI responsibly, without slowing down innovation by getting stuck in compliance processes.
It helps you turn governance from a theoretical checkbox into a practical, day-to-day capability that actually fits how your team works. With trail, you can plug governance directly into your stack using reusable templates, flexible frameworks, and smart automation. That means less manual work for compliance officers and developers alike, but more consistency without having to reinvent the wheel every time.
As a result, trail bridges the gap between tech, compliance, and business teams, making it easy to coordinate tasks along the AI lifecycle. It reduces overhead while boosting oversight, quality, and audit-readiness. Because real AI governance doesn’t live in PDFs, wiki pages, and spreadsheets — it lives in the daily doing.
If you want to make responsible AI your competitive advantage, let us help you — we are happy toexplore the right solution for you in a conversation. If you want to continue with your AI governance learning journey, you can do sohere with our free AI governance framework.
Your current AI strategy is likely costing you more than you think.
The rapid, uncontrolled adoption of various AI tools has created a costly “AI tax” across the enterprise, stifling true innovation.
This report explores the pivotal shift from fragmented AI tools to unified, collaborative platforms.
Learn how to move beyond scattered adoption to build a sustainable, cost-effective AI ecosystem that will define the next generation of industry leaders.
In this report, you’ll learn how to:
Benchmark your company’s progress against the latest enterprise AI adoption trends.
Expose and eliminate the hidden “AI tax” that is draining your budget and stifling innovation.
Build the business case for a unified AI platform that drives ROI, collaboration, and security.
Create a framework that empowers grassroots innovation without sacrificing centralized strategy and governance.
Design a future-proof roadmap for AI integration that scales with your enterprise and adapts to what’s next.
Your roadmap to a scalable, future-proof AI strategy is one click away.
The convergence of AI and AR/VR is changing the way we engage with, explore, and even create content for virtual worlds. This convergence is adding intelligence, realism, and adaptability to immersive experiences like never before, enhancing the potential of AR/VR significantly.
AI adds intelligence, personalisation, and adaptability to AR and VR interactions, thereby enhancing the degree of responsiveness and smoothness of the system for user needs.
This convergence of technology is more than just an innovation, it represents a significantly growing industry; According to a study of Verified Market Research, the AR and VR market surges to USD 214.82 billion by 2031, propelled by 31.70% CAGR.
At the same time, PwC predicts that AI advancements in business functions like training simulations, remote work, and cross-location teamwork will greatly enhance VR and AR applications, contributing $1.5 trillion to the economy by 2030.
Additionally, the AR and VR consumer segment is set to soar as well. IDC estimates that global expenditure on AR/VR will exceed $50 billion annually by 2026, with AI personalisation driving demand.
In addition, the AI-in-AR/VR sector is projected to experience a growth rate of more than 35% CAGR in the next few years, highlighting the transformative influence of intelligent algorithms on immersive technologies.
This rapid expansion illustrates the need for advanced virtual experiences powered by AI in almost every sector. It is predicted that by 2029, the number of users in the AR & VR market worldwide is expected to reach 3.7 billion.
As AI improves the functionality of AR/VR applications, it will change how we interact with the digital world and the real world, merging virtual and real experiences in ways we have just begun to scratch the surface of.
The integration of AI with AR/VR technologies
The growth of AR technology is quite evident with the success of Vuzix Blade and Epson Moverio’s step into the enterprise world. Imagine a scenario in which AI interacts with you on a personal level and caters to your every need while guiding you through a new virtual world that seems similar to our physical world.
Undoubtedly, from enterprises to personal users, the use cases are limitless. Remote workers, for example, can use AR glasses to get real-time guidance from AI virtual assistants that enable them to work more productively. Users can expect advanced navigation, e.g., guided navigation, virtual try-ons, and much more. Some remote workers could receive real-time assistance through virtual AI helpers.
On one hand, with the lines blurring between the physical and virtual worlds, the integration of AI with AR and VR will cross new boundaries and significantly enhance user experience.
On the other hand, AI is changing the game for creators of AR and VR technologies by completing repetitive tasks like 3D modeling and creating textures, allowing creators to make important, high-level decisions. Immersive experiences have also become easier to create due to AI tools, which allow unrestricted real-time rendering, physics simulation, and dynamic lighting.
AI systems assess usage patterns and modify content depending on prior encounters, preferences, and even emotions. A recent survey by PwC found that 55% of individuals are prone to patronising companies that offer personalised services, further demonstrating the strength of personalization.
In AR/VR, this transition leads to the creation of animated virtual universes that adapt to the user’s inputs and wishes, resulting in spaces that are highly personalised and pleasing to satisfy the users’ needs.
2. AI-powered optimisations
The impact of AI on XR systems is evident as its applications boost motion anticipation, compression, and rendering to achieve seamless and consistent visuals.
NVIDIA CloudXR employs AI-driven pose prediction for user movement tracking, which enhances motion responsiveness and stream relays in cloud-streamed XR applications. Furthermore, real-time frame scaling of lower resolutions through DLSS enhances visual sharpness without increasing GPU demand.
The ability to cut bandwidth consumption dramatically through AI-powered video compression enhances the fluidity of AR/VR streaming over conventional networks. Dynamic foveated rendering from Meta’s XR ecosystem advancements and Qualcomm’s Snapdragon Spaces utilizes AI to optimize detail-rich areas for user gaze focus while expecting lesser detail in peripheral views. Such improvements significantly improve immersion capabilities for users.
3. Enhancing emotional intelligence for AR/VR applications through AI
The realm of AR and VR is being transformed by AI, especially in the areas of emotion recognition. Utilizing machine learning techniques, AI systems are capable of discerning emotions through voice, posture, and even subtle facial expressions.
Such capabilities can dynamically tune AR/VR experiences. For instance, an emotionally intelligent AI VR game could tailor its story or modify the game’s level of difficulty based on the emotional feedback received from the player. Similarly, emotion-sensitive AI could improve responsiveness in strategy educational games by changing content to meet a student’s emotional needs.
Researchers also suggest that AI designed to recognize emotions can enhance emotional engagement, or more basic cues could be used to guide remotely controlled environments. context of gaming
4. AI for natural language & gesture control in AR/VR
AI is transforming the manner in which people engage with AR and VR technology through natural language processing and gesture control. Hands-free operation is made possible through voice recognition powered by AI, such as Google’s Dialog Flow.
On the gesture recognition front, AI-powered hand tracking is transforming how users interact in VR. Leap Motion’s AI sensors allow for precise hand movements and gesture recognition in VR applications, making them as responsive as real-world interactions.
Gesture tracking also allows for interaction with the Microsoft HoloLens AR smart glasses, integrating touch-free commands in the medical, industrial, or enterprise applications. Bringing digital experiences closer to the real world, these features deepen the immersion and usability of AR/VR systems.
5. AI augmentation of virtual beings (NPCs) in AR/VR
AI modifies virtual humans and NPCs in AR/VR systems by automating their responsiveness and emotional sensitivity.
Avatars and NPCs (non-player characters) powered with AI technology facilitate immersion through real-time context-responsive dialogues powered by Natural Language Processing (NLP), computer vision, and deep learning. In gaming and social VR, AI-powered NPCs are interacting with users on a more sophisticated level.
NPCs with personalities, memory, and emotional intelligence can now be created, enhancing the engagement level in VR storytelling and multiplayer gaming. These advancements in AI-engagement are redesigning user immersion in AR/VR systems as interactions become less mechanical and more lifelike with sociability and emotions.
6. AI-powered virtual worlds: Bridging the gap between digital and reality
NVIDIA’s Omniverse employs AI photorealistic modeling and physics simulation to enable seamless collaboration in virtual spaces. Photorealistic environments are explorable in real-time.
Epic Games’ Unreal Engine 5 uses AI-based procedural techniques for the creation of untamed and lifelike explorable terrains. In social VR, Inworld AI and Charisma.AI animate NPCs with self-adaptive dialogue systems and emotional intelligence, transforming avatars into engaging personas.
Advances in AI illumination techniques, AI-powered physics, and object recognition open new frontiers where realism transforms immersion, making the world more wondrous.
While enhancing the end user experience, AI is also enhancing AR/VR creators’ capabilities in several ways.
AI-assisted 3D content creation and world building
One of the most challenging tasks for AR/VR developers is creating high-quality 3D assets and environments.
World generation and asset creation are now automated with AI. NVIDIA’s Omniverse and Epic Games’ Unreal Engine 5 employ AI-powered procedural generation to construct incredibly detailed, photorealistic landscapes with little human intervention. Additionally, AI tools like Promethean AI, which help artists by automatically generating 3D assets, are becoming more common.
Data-driven decision-making for AR and VR creators using AI technologies
AI assists AR and VR creators with making data-driven decisions on user behavior, level of engagement, and overall experience using performance metrics.
User interaction with virtual environments is monitored through advanced analytics systems like Niantic’s Lightship VPS, Unity Analytics, and others, enabling developers to improve game design, mechanics, user interfaces, and overall user engagement.
AI sentiment analysis and interaction heatmaps are utilized by Meta’s Horizon Worlds to monitor player interaction, enabling improvements in social VR space features and functionalities.
Additionally, the spatial understanding of how users interact with AR technologies is facilitated through AI-powered technology in Google’s ARCore, enabling brands to construct unique, immersive advertisements.
AI approaches to A/B testing, forecasting, and user experience customization enable AR and VR creators to define parameters on monetization, engagement, immersion, and interaction without being decisive.
A time of unified, intelligent engagements
The advent of AR/VR alongside AI is revolutionizing the way digital content is created and consumed. The report from Gartner does suggest that 40% of AR/VR applications from the consumers’ perspective in 2026 will be integrated with AI; a clear testament to the potential that such intelligent immersive applications possess.
Whether it’s gaming, virtual meeting spaces, or working on creative ideation, the core merger of AI and AR/VR is rendering boundaries obsolete.
In the words of Nvidia’s CEO, Jensen Huang, integration of AI within immersive tech is not resizing or enhancing the relevance of the technology but rather altering the paradigm of interacting with the computer. For creators, it’s a great time to explore various tools and devices, while for consumers, it is the beginning of adaptive and tailored interactions.
With every innovation, it seems like the world where the digital space doesn’t stand out from our reality, it simply merges, is not so far. In fact, it seems like it has the potential to rework the definition of work interactions and creativity.
A few weeks ago, I saw a post on Instagram that made me laugh; it was about someone’s grandmother asking if she should invest in AI. That really struck a chord. Right now, AI is everywhere. It’s overhyped, misunderstood, and somehow both intimidating and irresistible.
I work with executives, product managers, and board members every day who are all asking the same questions: When should we invest in AI? How do we know if it’ll be worth it? And once we do decide to invest, how do we make sure we actually get a return on that investment?
After more than a decade building AI products – from chatbots at Wayfair to playlist personalization at Spotify to Reels recommendations at Instagram, and leading the AI org at SiriusXM – I’ve seen the difference between AI that delivers and AI that drains.
This article is my attempt to help you avoid the latter, because here’s the thing: AI is powerful, but it’s also expensive. You have to know when it makes sense to build, and how to build smart.
So, let’s get started.
Define the problem first – AI is not the goal
Let me be blunt: if you can’t clearly articulate the business problem you’re trying to solve, AI is probably not the answer. AI is not a goal. It’s a tool. A very expensive one.
I always come back to something Marty Cagan said about product management:
“Your job is to define what is valuable, what is viable, and what is feasible.”
That same principle applies to AI investment. You need:
A clear business objective
A way to quantify the value (revenue, cost reduction, efficiency, customer satisfaction, etc.)
A realistic budget based on your unique context
If you’re a nonprofit, you might ask how many people you’re serving and what it costs. If you’re a startup, it’s how many paid users you expect to gain and your acquisition cost. For a teacher, it’s student outcomes per dollar spent. The same logic applies to AI.
Let’s say you do have a clear problem. Great. Now the question becomes: What value will AI actually bring?
Sometimes the ROI is direct and measurable. For example, it could be revenue growth from improved ad targeting or cost savings by identifying high-risk loan applicants more accurately.
Other times, the value is indirect but still impactful, such as:
Assign potential impact scores (quantitative or qualitative)
Use forecasting, heuristics, or pre/post analysis to estimate the lift
For example, back when I was working on Reels recommendations, we modeled how a small bump in conversion rate could translate into tens of millions of dollars in additional revenue. It doesn’t need to be perfect – it just needs to be honest.
At the Generative AI Summit Silicon Valley 2025, Vishal Sarin, Founder, President & CEO of Sagence AI, sat down with Tim Mitchell, Business Line Lead, Technology at the AI Accelerator Institute, to explore one of the most urgent challenges in generative AI: its staggering power demands.
In this interview, Vishal shares insights from his talk on the economic imperative of breaking power efficiency barriers and rethinking the AI stack to make generative AI scalable and sustainable.
The power problem in Generative AI
Tim Mitchell: Vishal, great to have you here. Can you start by summarizing what you spoke about at the summit?
Vishal Sarin: Absolutely. While generative AI has opened up enormous opportunities, it’s facing a major bottleneck: power efficiency. The massive energy requirements of AI workloads threaten their economic viability.
My talk focused on the urgent need to break through these power efficiency barriers; not through incremental tweaks, but by rethinking the entire AI stack, from chips to cooling. We need radical innovation to make generative AI truly scalable and sustainable.
Opportunities across the AI stack
Tim: Where are the biggest opportunities to reduce power consumption across the AI stack?
Vishal: There are improvements possible across the stack, such as power generation and distribution, and even at the network level. But the most foundational leverage point is in computation and memory.
If you look at the power consumption of generative AI workloads, memory access and data movement dominate. So, optimizing compute and memory together, what we call in-memory compute, is a massive opportunity to cut both cost and energy use. It’s where you get the most ROI.
The promise of in-memory compute
Tim: In-memory compute sounds like a major shift. Can you elaborate?
Vishal: Definitely. Today’s architectures are built on the von Neumann model, which separates compute and memory. Data constantly moves between memory and processor – an extremely power-hungry process.
In-memory compute integrates computation closer to the memory, significantly reducing data movement. This architectural change could improve power efficiency by orders of magnitude, especially for inference tasks in generative AI.
The role of accelerators and SLMs
Tim: What about hardware accelerators like GPUs? Where do they fit into this picture?
Vishal: GPUs and other accelerators are critical but also contribute significantly to energy usage, largely because of memory bandwidth. Even with very efficient compute units, moving data to and from memory becomes a bottleneck.
To go beyond current limits, we need a paradigm shift that combines the strengths of accelerators with architectural innovations like in-memory compute. That’s where the next wave of performance and efficiency gains will come from.
Tim: Does this mean small language models (SLMs) are also part of the solution?
Vishal: Yes. SLMs are more lightweight and reduce the need for massive infrastructure to run inference. When designed and trained efficiently, they can offer comparable performance for many applications while drastically cutting down power and cost.
They’re not a replacement for large models in every case, but they play an important role in making AI more accessible and sustainable.
Cooling and infrastructure innovation
Tim: Beyond compute, how important are cooling and energy systems?
Vishal: They’re essential. High-density AI infrastructure creates tremendous heat, and traditional cooling is no longer enough.
Innovations like liquid cooling and better energy recovery systems are necessary to keep power usage in check and manage operational costs. These systems need to evolve alongside the compute stack for AI infrastructure to be economically viable at scale.
A path toward sustainable scaling
Tim: Looking ahead, what gives you optimism about solving these challenges?
Vishal: What’s exciting is that we’re at a turning point. We know where the problems are and have clear paths forward, from architectural innovation to smarter energy use.
The industry is no longer just chasing performance; it’s aligning around efficiency and sustainability. That shift in mindset is what will drive generative AI toward long-term viability.
Final thoughts
Vishal Sarin’s vision for the future of generative AI is clear: breaking power efficiency barriers isn’t optional; it’s a necessity. By rethinking compute architectures, embracing small models, and innovating across the AI stack, the industry can achieve both performance and sustainability.
As the field matures, these breakthroughs will determine whether generative AI can scale beyond hype to deliver enduring, transformative value.
We are making Quantum Leaps. I am not referring to the 80s/90s TV show, but rather, I am referring to quantum computing and competing for better and faster artificial intelligence.
Quantum computing is a field that excites me to my core. I’ve always been driven by pursuing what’s next, whether mastering tactics in the Marines or navigating complex policy challenges in government.
Quantum computing feels like the ultimate “what’s next.” Its potential to solve problems in seconds that would take today’s supercomputers millennia is a quantum leap. I talked a bit about Quantum Computing in one of my recent newsletters.
However, potential doesn’t turn into reality without investment of time, money, and strategic resources. My experience has shown me that technological superiority is a strategic advantage, and right now, nations and companies worldwide are racing to claim the quantum crown.
We risk falling behind if we don’t pour resources into research, development, and deployment. This is more than an opportunity; it’s a call to action. We must invest heavily and deliberately to ensure quantum computing becomes a cornerstone of our competitive edge.
AI alone cannot navigate the intricate challenges of mapping regulatory landscapes or developing sustainable solutions to meet our world’s diverse energy needs.
“Within 10 years, AI will replace many doctors and teachers; humans won’t be needed for most things.” – Bill Gates
Bill Gates’s premonition that only a few fields will survive over the next 10 years insinuates massive shifts happening, and rather quickly. Welcome to the quantum computing era.
As we are trending towards a new era of AI, called quantum computing, it becomes increasingly evident that our approach to both data centers and the broader energy grid needs to change.
Next to Bill Gates’s statement, AI is continually seeping into every industry and every corner of life. I believe this is causing and will continue to cause a surge in demand for advanced computing power like never before, which will not only drive the need for redesigning smarter, more efficient data center strategies but will also require a fundamental advancement of our energy grid infrastructure.
To start with, we must focus on data centers and our energy grid; it’s important to illustrate at a high and broad level how we get push-button AI at our fingertips.
See Figure 1 below
The underlying process that supports modern AI begins with power generation. Energy is produced at large-scale facilities, ranging from nuclear reactors (both current 3rd-generation and the emerging 4th-generation designs), coal-fired plants, wind farms, and solar arrays, which convert various energy sources into electricity. This electricity then travels through an extensive distribution network of power lines and substations before reaching data centers. That is the energy grid infrastructure.
Inside these data centers, thousands of powerful servers process and store vast amounts of data, running complex AI algorithms and machine learning models. These facilities employ advanced cooling systems and high-speed networking infrastructure to ensure optimal performance, allowing rapid global data transmission.
When a user interacts with an AI application, whether a virtual assistant or a personalized recommendation engine, the input is processed at these centers through model inference, and the output is swiftly delivered back via the internet to consumer devices.
Figure 1
In layman’s terms, our modern AI experience relies on the vital integration of robust energy grids and sophisticated data centers, flawlessly powering the technologies at our fingertips. This interconnected infrastructure is necessary for delivering the immediate, push-button AI capabilities that are so commonplace now that we tend to take them for granted.
Advancing the energy grid: Nuclear or solar, which is better for the emergence of quantum computing?
Solar and nuclear power are set to emerge as the two dominating sources for our future energy mix. Solar energy is a game-changer due to its virtually limitless potential, rapidly declining costs, and the strides we’ve made in efficiency and storage technology.
As our digital demands continue to surge, especially with the rise of advanced computing and quantum technologies, solar’s scalability makes it a feasible choice for powering everything from sprawling data centers to localized grids. At the same time, nuclear energy is indispensable because it provides reliable, around-the-clock baseload power with minimal carbon emissions.
With next-generation advances like small modular reactors addressing traditional safety and waste concerns, nuclear power is well-positioned to deliver the steady energy output necessary to support our ever-growing, high-demand digital infrastructure.
With nuclear and solar together, these two sources balance flexibility with stability, making them my top picks for the future.
Based on the photo in Figure 2 below, solar currently contributes less than wind and hydro, but it’s set to catch up and eventually overtake them. Solar’s lower current share is primarily due to its relatively recent adoption and earlier cost barriers, whereas wind and hydro have been established for decades.
However, I’m excited about the rapid cost declines in solar panel technology, energy efficiency improvements, and storage system advancements that address intermittency.
Unlike hydro, which is limited by geography, or wind, which requires consistent breezes, solar panels can be deployed almost anywhere, with considerations, i.e., my references to Washington State later in this writing. As energy demands grow, especially with emerging technologies like quantum computing, I expect solar to scale quickly to meet nuclear energy as a complete hybrid energy strategy.
Figure 2
Nuclear: As quantum computing matures and its demands for energy reliability, efficiency, and stability increase, the debate over the ideal energy source intensifies.
Nuclear power has very low CO₂ emissions during operation and exceptionally high energy density, offering a compact but potent solution. Its ability to generate massive power from a relatively small footprint makes it an attractive option for powering data centers that support quantum computing.
However, nuclear reactors come with a lot of challenges. The production of radioactive waste, which requires long-term, secure management, and the inherent risks associated with potential accidents, remain top concerns. Additionally, the regulatory landscape for nuclear power is intricate, necessitating continual human oversight and specialized expertise to ensure safe operations.
With that said, let me reference Bill Gates’s perspective below: one area where jobs will continue to reign over AI in the future is in energy experts.
“2. Energy experts: The guardians of power
The energy sector is too vast and intricate for AI to manage alone. Whether dealing with oil, nuclear power, or renewables, industry experts are required to navigate regulatory landscapes, strategize sustainable solutions, and handle the unpredictable nature of global energy demands.”
Solar: On the other side of the debate, solar power is a renewable and environmentally friendly alternative. With minimal operational emissions and the potential for scalability, solar reactors can leverage the sun’s abundant energy. This scalability is particularly appealing for decentralized energy production and for applications where geographical distribution is advantageous.
Whenever I return to California from Ireland, my flight path often passes 40,000 feet over Arizona, where a colossal solar farm sprawls across the desert. The farm is called the Agua Caliente Solar Project.
Even when I’m cruising from San Diego to Phoenix, its vast expanse is unmistakable, visible at 70 mph on the highway or from high above. The Agua Caliente Solar Project is a 290 megawatt (MWAC) photovoltaic power station, built in Yuma County, Arizona, using 5.2 million cadmium telluride modules made by the U.S. thin-film manufacturer First Solar. It was the largest solar facility in the world when the project was commissioned in April 2014.[1][2]
While the striking installation thrives in the sunny, arid conditions of Arizona, replicating it in regions like Washington State could be more challenging due to:
There is a need for vast, open, and flat land, conditions less common in much of Washington, though some areas offer suitable terrain.
The abundant, consistent sunlight is essential for large-scale solar farms, which is less prevalent in Washington compared to Arizona.
Here is an aerial photo – Figure 3 – of the farm from about a height of 10,000 feet.
Figure 3
Yet, solar power systems face their own set of hurdles. Large-scale solar installations demand very large land areas, which can be a limiting factor in densely populated or resource-constrained regions.
Additionally, the environmental impact of manufacturing solar panels, including resource extraction and waste generated at the end of their lifecycle, cannot be overlooked. Like my example of Washington State, variability in solar energy production due to weather conditions further complicates its reliability as a sole energy source for critical applications like quantum computing.
When evaluating these trade-offs, it’s important to consider the specific energy needs of quantum computing. Quantum computing centers require not only massive, uninterrupted power but also an energy infrastructure that can scale with the rapid growth of data and processing demands.
Nuclear reactors, particularly next-generation designs, could provide the consistent, high-output energy necessary to run these power-hungry centers efficiently. In contrast, while solar power offers a cleaner, more renewable option, its dependency on external factors like sunlight means it might best serve as a supplementary source rather than the primary backbone of energy supply for such high-stakes applications.
Out with the old, in with the new: Leaping from 3rd generation nuclear, to 4th generation
The need for such sophisticated infrastructure becomes even more important as the demand for AI and quantum computing applications continues to grow.
Although current 3rd-generation nuclear reactors can power today’s data centers and support quantum computing, there is a convincing argument to expedite shifting to 4th-generation reactors.
These advanced reactors promise enhanced safety features, improved fuel efficiency, and reduced radioactive waste. The U.S., for example, is actively pursuing these 4th-generation reactors through initiatives like the Department of Energy’s Advanced Reactor Demonstration Program, with demonstration projects expected in the early 2030s and broader deployment possibly by the mid-to-late 2030s.
Meanwhile, countries such as China and Russia are already experimenting with advanced reactor designs like China’s HTR-PM and Russia’s BN-800, though no nation has yet deployed a large fleet of fully commercial 4th-generation reactors.
The integration of AI and quantum computing is driving a transformative rethinking of both energy generation and data center ecosystems. Advanced power generation from the next wave of nuclear reactors to innovative renewable energy sources is going to be standardly needed in meeting the escalating energy demands of these emerging technologies.
As our reliance on AI and quantum computing grows, so does the need for human expertise to navigate the complex regulatory and technical challenges inherent in this evolution.
Whether nuclear or solar reactors ultimately prove superior in specific cases may depend on regional needs, technological breakthroughs, and the balance between efficiency, safety, and sustainability in the long term.
So, it’s highly unlikely that the grid and the economy would go with one or the other as we emerge into the era of quantum computing, but rest assured, they will both be absolutely necessary.
The 4th-generation nuclear reactors are an increasing necessity for quantum computing because they provide the ultra-stable, high-density energy needed for sensitive quantum systems.
Unlike 3rd-generation reactors, these advanced designs offer enhanced safety features, more consistent power output, and improved fuel efficiency, all while reducing radioactive waste. These improvements are critical for powering the data centers that drive AI and quantum computing, ensuring a resilient, sustainable energy grid for future technological advancements.
Below in Figure 4 is a comparative chart outlining some of the main pros and cons of nuclear power versus solar power. This chart summarizes key points to consider when comparing nuclear and solar power. Each energy source has distinct advantages and challenges that must be weighed in light of factors such as environmental impact, reliability, cost, safety, and waste management.
Figure 4
Rethinking data centers
In my time as a Marine, I learned the value of strategic positioning, never putting all your resources in one vulnerable spot. That lesson resonates with me now as I look at the digital landscape.
My military background taught me to anticipate risks and plan for redundancy, and that’s exactly what decentralized data centers offer. They’re not just infrastructure; they’re a strategic asset, and I believe investing in them is non-negotiable if we want to stay ahead in the digital race.
To realize Bill Gates’ statement, which I originally referred to in this writing, I believe the final shift to his proposed future state reality will be a commoditized approach to data centers; again, similar to my gas station theory, I mention below.
In my view,
“We are on the brink of a transformation that I would call the ‘real estate data center market’ (watch video), where data centers become as ubiquitous as gas stations.
This vision is driven by the fact that our growing population and escalating energy demands necessitate a robust, reliable, and scalable power supply.
With a decentralized data center environment as frequent as gas stations, less strain will be placed on the environment, and AI will be more productive.
Imagine if a town the size of 500,000 people only had one gas station. It would not be productive, and the strain on supply would be unfeasible. Now, if you have 500 gas stations, that is per 10 people, then the situation gets much more manageable.”
Data centers are not typically seen as attractive-looking landmarks. They are also not typically used for anything other than a data center. However, with the remote work society, and logistics and distribution changing for things like shopping malls, movie theaters, and skyscrapers, there sure is a lot of empty building space sitting around that can be repurposed into mixed-use complexes and buildings as data centers.
There are many landmarks today that have been turned into data centers, called adaptive reusage, but otherwise would have been decommissioned and destroyed.
For example, historic structures like Milwaukee’s Wells Building and Portland’s Pittock Block have been repurposed into state-of-the-art data centers, preserving their architectural legacy while meeting modern technological demands.
Many of these buildings have historical value and meaning, and are not such a “community eyesore” and very “dystopian” looking. For example, the Western Union Building, 60 Hudson Street, has historically served as an office and telecommunications hub.
Today, however, it is primarily used as a data center and colocation facility, making it a prime example of adaptive reuse. While its core function is data center operations, elements of its traditional usage, such as office space and support services, still remain, reflecting its multifaceted role in New York City’s evolving infrastructure.
These buildings were once at risk of demolition or decommissioning as their original uses became obsolete. Instead of letting them be destroyed, innovative adaptive reuse projects have transformed these historic landmarks into modern data centers.
This approach not only preserves architectural heritage but also meets today’s growing technological needs. For instance, projects have repurposed structures like Milwaukee’s Wells Building and Portland’s Pittock Block, buildings that might have otherwise been demolished, into state-of-the-art data centers.
In Figure 5, the data center on the left, though not unattractive, feels plain and lacks character, intrigue, and meaning. In contrast, the images of 60 Hudson Street on the right showcase a building rich in substance, personality, and historical charm.
From a purely architectural perspective, many contemporary data centers follow a utilitarian, box-like design that prioritizes efficiency, cooling, and security over aesthetics. They often feature minimal ornamentation, subdued façades, and large footprints for equipment. While this design approach is practical, it can lack the visual appeal and historic character seen in older structures.
By contrast, 60 Hudson Street exemplifies an era of architecture in which buildings were designed to showcase craftsmanship and artistry. Built in an Art Deco style, its brick façade, ornate lobby detailing, and dramatic setbacks reflect the period’s emphasis on ornamentation and grandeur.
Even after being repurposed as a data center and telecommunications hub, it retains much of its original design intent and ambiance, giving it a sense of place and history that many newer facilities don’t replicate.
In short, the difference lies in the guiding priorities behind each building’s construction. Modern data centers focus on function first, large-scale power capacity, robust cooling, and physical security, whereas older buildings like 60 Hudson Street were shaped by an architectural tradition that valued aesthetic richness and craftsmanship as essential parts of a structure’s identity.
Figure 5
This article proposes that data centers be integrated as a component of modern residential developments. The idea is to design mixed-use projects where data centers and residential units coexist in the same vicinity or even within the same building complex, creating synergies such as shared infrastructure, improved connectivity, and more efficient land use, rather than literally housing residents within a data center facility.
The other telltale sign about a commoditized approach to data centers comes from Sam Altman. In a recent interview, OpenAI co-founder Sam Altman said:
“We’re going to see 10-person companies with billion-dollar valuations pretty soon…in my little group chat with my tech CEO friends, there’s this betting pool for the first year there is a one-person billion-dollar company, which would’ve been unimaginable without AI. And now [it] will happen.”
If both statements become true, imagine the data center requirements. I repeat my gas station analogy.
If we accept Bill Gates’ perspective on the survival of certain energy sector jobs and Sam Altman’s prediction about the rise of hyper-efficient, lean companies, then the infrastructure supporting these trends, data centers, will need to evolve dramatically.
The idea is that data centers could become as ubiquitous and commoditized as gas stations. Just as gas stations are scattered throughout our landscapes to provide quick, localized fuel access, future data centers might be deployed in a decentralized manner to meet the explosive demand for computational power.
This transformation would be driven by the exponential growth of AI-driven applications, the need for ultra-low latency processing, and the energy requirements of quantum computing.
With advances in modular design, improved cooling systems, and energy efficiency, smaller data centers could be rapidly deployed in nearly every urban and rural corner, supporting the next wave of technological innovation.
While challenges like regulatory hurdles, cybersecurity, and capital expenditure remain, the convergence of these trends suggests that a commoditized, widely distributed data center model is feasible and likely necessary to sustain the future digital economy.
Feeding off my gas station analogy, let’s look at power substations. Imagine Chicago’s power grid: the city relies on around 1,300 substations to distribute electricity efficiently across neighborhoods.
These substations act as critical hubs that step down high-voltage electricity from power plants to levels safe and usable by homes and businesses. Now, consider the digital equivalent of these substations, data centers.
As our reliance on digital technologies grows, especially with the advent of AI and quantum computing, we need a similarly robust network to process, store, and distribute data. Just as substations are strategically positioned throughout Chicago to ensure reliable power delivery, data centers need to be widely distributed to meet increasing digital demands.
This analogy suggests that as our energy infrastructure scales up to support a city like Chicago, our digital infrastructure must also expand proportionately, necessitating more localized data centers to ensure low-latency, high-performance computing across the urban landscape.
Rethinking our digital infrastructure, I believe it’s ever more important to evolve data centers into a decentralized network as ubiquitous as gas stations. In today’s rapidly expanding digital landscape, which is driven by the exponential growth of AI and quantum computing, the demand for computational power is skyrocketing.
Just as in my example above, a town with only one gas station for 500,000 people would struggle with supply. Relying on a few centralized data centers creates bottlenecks and latency issues.
A commoditized model, where data centers are as common as power substations in a city like Chicago, would distribute computing resources evenly, ensuring ultra-low latency and high-performance processing across both urban and rural areas.
My vision aligns with Bill Gates’ perspective on transforming energy sectors and Sam Altman’s prediction of hyper-efficient, lean companies emerging in our digital future.
With modular designs, improved cooling, and energy efficiency, widespread, localized data centers are feasible. They are becoming the lifeblood for sustaining our digital economy, reducing environmental strain, and supporting the next wave of technological innovation.
Leaving you my perspective
As an AI venture capitalist, I am shaped by my years as a U.S. Marine and my extensive experience in government. These roles have given me a front-row seat to the indispensable role that infrastructure and policy play in safeguarding national security and driving economic resilience.
Today, I stand at the intersection of technology and investment, and from where I see it, the future hinges on bold, strategic moves in three critical areas: next-generation data centers, quantum computing, and advanced energy solutions. These aren’t just trends or buzzwords; they are the pillars of a secure, competitive, and prosperous tomorrow.
Technology alone doesn’t win the day; policy and leadership do. My years in the public sector drilled this into me. I’ve been in the rooms where decisions are made, and I’ve seen how effective collaboration between government and industry can turn ideas into action.
Right now, we need thinking and doing of substance vs more of the superficial developments we have seen with AI. We need regulatory frameworks that don’t stifle innovation but propel it forward while keeping security and sustainability front and center.
This isn’t about bureaucracy for its own sake. It’s about creating an environment where bold investments can flourish responsibly into technologies of substance, not superficial trends and hype.
Policymakers must work hand in hand with industry leaders to craft guidelines that protect our national interests, think cybersecurity, data privacy, and environmental impact, without slowing the pace of progress. My experience tells me this is possible. When the government and private sector align, the results are transformative. We need that alignment now more than ever.
As an AI venture capitalist, I’m observing these shifts and urging us to act on them. I call on my fellow investors, government officials, and industry pioneers to champion these strategic investments with me.
By rethinking our approach to data centers and advancing the energy grid infrastructure, we are creating the next wave of digital innovation and building a nation that’s secure, competitive, and ready for what’s ahead. I’ve seen what’s possible when we commit to a vision, whether on the battlefield, in the halls of government, or the boardroom.
Let’s not wait for the world to change around us. Let’s be the ones to drive that change.
You can connect with Paul on LinkedIn and through his CV site.
Catch up on every session from the AIAI Silicon Valley with sessions across 3 co-located summit featuring the likes of Anthropic, Open AI, Meta and many more.
Unlike traditional AI systems that rely on step-by-step human input, agentic AI represents the next evolution: autonomous agents capable of ingesting information, executing tasks, and independently delivering end-to-end outcomes.
These agents can undertake multistep processes, linking APIs, databases, and workflows, to tackle complex problems without constant oversight. As businesses aim to streamline operations and cut down on manual bottlenecks, agentic AI signals a shift from human-in-the-loop to human-on-the-loop management.
IBM and Oracle’s relationship stretches back years, with joint efforts to optimize middleware, databases, and cloud services. Their agentic AI partnership builds on prior collaborations, such as the 2018 integration of IBM Cloud with Oracle’s database services. It reflects a mutual strategy to deliver enterprise‑grade AI tools at scale. By pooling IBM’s AI research and Oracle’s cloud infrastructure, they can offer customers seamless, cloud‑native workflows that span both vendors’ ecosystems.
watsonx Orchestrate: Automating workflows
On May 6, 2025, IBM and Oracle unveiled a significant expansion of their alliance: IBM’s watsonx AI portfolio, including watsonx Orchestrate and the new Granite AI models, will be directly available on Oracle Cloud Infrastructure (OCI).
Unlike point solutions, these tools are deeply embedded in OCI’s core services, allowing agents to run natively alongside data and apps—no extra pipelines or connectors needed.
At the heart of this expansion is watsonx Orchestrate, a drag‑and‑drop interface for building AI agents. Users can configure agents to perform tasks like data extraction, reconciliation, and approval routing by simply arranging modular “action blocks.” These blocks invoke pretrained models or custom scripts, then hand off outputs to the next step: creating a no‑code pipeline that frees business users from writing scripts or managing cloud resources.
Complementing Orchestrate are the Granite AI models, pretrained on industry‑specific datasets for finance, supply chain, and customer service sectors. By offering models tailored to common enterprise use cases, IBM and Oracle reduce the time and expertise needed to fine‑tune agents. Organizations can deploy a Granite model for invoice processing or customer‑support triage out of the box, then further customize it with proprietary data.
OCI: Built for agentic AI
IBM’s CEO, Arvind Krishna, set the tone at THINK 2025 when he declared that “the era of AI experimentation is over,” signaling a shift toward production‑ready AI agents that deliver measurable business outcomes. Analysts note enterprise customers increasingly demand turnkey, autonomous workflows rather than proof‑of‑concept demos.
Meanwhile, technology partners are already preparing for this evolution. At the same event, IBM highlighted its integration of webMethods Hybrid Integration, designed to “replace rigid workflows with intelligent, agent‑driven automation” across apps, APIs, and file transfers in a hybrid cloud environment.
Running agentic AI tools natively on OCI delivers several benefits:
Reduced latency: Agents access data stored in OCI without egress fees or cross‑cloud hops.
Scalability: OCI’s elastic infrastructure dynamically allocates resources as agents spin up or idle.
Simplified management: Centralized monitoring and billing within OCI avoid the friction of multicloud administration.
IBM and Oracle designed Orchestrate for both citizen developers and IT professionals. Prebuilt templates for common tasks, such as “Process Purchase Orders” or “Resolve Support Tickets”, enable rapid adoption. For more technical teams, APIs and SDKs allow embedding agentic functions into custom applications. This dual approach democratizes AI automation, letting frontline employees build solutions while keeping advanced customization in the hands of developers.
Finance: Agents reconcile transactions across ERP systems, flag anomalies, and generate reports, cutting close‑of‑month times by up to 40 percent.
Supply chain: Agents monitor inventory levels, predict stockouts, and automatically reorder supplies when thresholds are crossed.
Customer service: Agents triage incoming tickets, draft responses, and escalate to specialists on complex issues, all within an enterprise service‑desk platform.
While Oracle and IBM take a joint approach, competitors are also racing to offer agentic AI. AWS Bedrock recently added “Agents” capabilities, and Microsoft Azure is integrating autonomous workflows into Power Automate. However, the IBM–Oracle deal stands out by uniting two major enterprise vendors and offering pretrained, domain‑aware models alongside low‑code orchestration tools in one cloud.
Cross‑cloud agents: Tools to manage agents that operate seamlessly across OCI, AWS, Azure, and on‑premises data centers.
Vertical AI catalogs: Expanded Granite‑style model libraries for healthcare, manufacturing, and legal.
Standardized governance: Industry frameworks to certify the safety, ethics, and compliance of autonomous agents.
However, challenges remain. Data privacy regulations may limit the scope of autonomous decisions. Organizations must guard against over‑automation, ensuring human oversight where necessary. Technical hurdles, such as integrating legacy systems, can also slow rollout.
The expanded IBM–Oracle partnership marks a significant milestone toward autonomous enterprise AI. By embedding watsonx Orchestrate and Granite AI models directly into OCI, the two companies have created a unified platform for building, deploying, and governing agentic workflows at scale. For businesses and developers, this means faster time to value, robust security, and the freedom to build fast on a cloud they already trust.
As agentic AI evolves, organizations that move early will be best positioned to unlock real efficiency gains and stay ahead of the competition through true end-to-end automation.
December 2028. Maria’s AI agent is negotiating simultaneously with twelve different vendors for her daughter’s upcoming birthday party.
Within minutes, it secured the perfect cake from a local bakery (after verifying their nut-free certification), booked an entertainer with stellar safety ratings, and coordinated custom goodie bags filled with each child’s favorite treats (after checking allergies and dietary restrictions with the other parents’ agents)—all while staying 15% under budget.
What would have taken Maria hours of calls, emails, and anxiety about vendor reliability now happens seamlessly through a web of agent-to-agent interactions powered by the new infrastructure explored in the previous post.
The revolution in web infrastructure we discussed in previous posts isn’t just theoretical—it’s enabling fundamental changes in how commerce, marketing, and customer service function. As agent passports and trust protocols become standardized, we’re witnessing the emergence of entirely new commercial paradigms.
With the recent release of Tasks by OpenAI, which equips ChatGPT—its consumer-facing AI—with the ability to perform tasks behind the scenes on behalf of users, it’s now easier than ever to envision a future where ChatGPT seamlessly navigates the web and handles complex operations for us.
ChatGPT can now set reminders and perform recurring actions
Today, we’ll explore how an agent-first internet will reshape domains like payments, marketing, support, and localization.
Agentic payments
Remember when online shopping first emerged, and entering your credit card details on a website felt risky? Card networks like Visa and Mastercard and banks like Chase and Barclays had to rapidly adapt to the digital realm, introducing new protocols like CVV codes and secure payment gateways to protect consumers and merchants alike. This evolution was pivotal in building trust and facilitating the e-commerce boom of the early 2000s, giving birth to digital payment giants like Stripe and PayPal.
This article was originally published here at AI Tidbits, where you can read more of Sahar’s fascinating perspectives on AI-related topics.
Similarly, the payment infrastructure that powers today’s internet was built around a simple dichotomy: card-present versus card-not-present transactions and the assumption that all payments are human-initiated.
The internet already faced a similar shift with the introduction of subscription payments in the early days of e-commerce, in which customers input their payment credentials once, allowing a merchant to charge them repeatedly in the future.
Recurring payments, now a dominant commerce mechanism projected to surpass $2.4T in spending by 2028, underscore how critical adaptive payment systems are to supporting global e-commerce. Yet, even more than a decade later, there are still countries like India that impose strict controls on recurring payments, highlighting the complexities of adapting systems to new paradigms.
But what happens when the legitimate transacting party isn’t human at all?
Digital payment systems are built around human users, employing measures like CVV codes and billing address verification to prevent fraud. These methods assume a human is initiating the transaction, making them ill-suited for autonomous agent transactions.
One major challenge is fraud detection and resolution—an area I intimately understand from my time as a PM at Stripe, where I worked closely with card issuers to develop sophisticated fraud prevention systems.
The current paradigm relies heavily on human behavioral patterns: typing speed, mouse movements, time spent reviewing checkout pages, and other signals that indicate legitimate human activity. But in an agent-driven world, these signals become obsolete.
During my time at Stripe, we saw how crucial these behavioral signals were for differentiating legitimate transactions from fraudulent ones. The shift to agent-driven commerce demands an entirely new approach. Rather than looking for signs of human behavior, we’ll need systems that verify agent legitimacy, authorization scope, and decision-making logic.
This shift raises critical questions for fraud prevention across banks (Chase, Barclays), card networks (Visa, Mastercard), and payment processors (Stripe, PayPal). For instance, how do you establish a chain of trust when an agent purchases on behalf of a user? How do you verify that an agent hasn’t been compromised or hijacked? These challenges require fundamentally rethinking our approach to transaction security and fraud prevention in an agent-driven ecosystem.
Fraud resolution in the era of AI agents
Future payment systems could introduce ‘agent wallets’ with granular spending controls, such as $100 limits for trusted merchants like Amazon and stricter caps for lesser-known websites. These wallets would integrate real-time fraud detection, submit cryptographic evidence for disputes, and maintain transparent, auditable records of agent actions tied to human authorization.
Visa could introduce an agent-specific flag to the existing payment protocols, indicating this payment was initiated autonomously, along with a trial of reasoning and actions leading to this payment. Meanwhile, Stripe might expand its SDKs to enforce programmable payment rules, ensuring alignment with user-delegated instructions (Stripe has already made its foray into Agentic payments with its recent SDK release).
Stripe’s new Agents SDK supports Vercel’s AI SDK, LangChain, and CrewAI
Beyond preventing fraud, agentic payments face fundamental economic and infrastructural challenges. The existing payment infrastructure wasn’t architected for the high-frequency, low-latency transactions that characterize agent interactions. Consider the standard pricing model of payment processors like Stripe: a 2.9% fee plus 30¢ per transaction.
While manageable for traditional e-commerce, this fee structure becomes prohibitively expensive when scaled to the myriad micro-transactions that agents might need to execute.
This pricing isn’t arbitrary—it reflects the complex web of stakeholders in the traditional payment chain. Card networks like Visa and issuers like Chase have built their business models around these transaction fees.
Interestingly, Stripe’s recent acquisition of Bridge, a stablecoin payment infrastructure provider, hints at a potential solution. By leveraging blockchain-based payment rails, companies could facilitate agent-to-agent transactions without incurring the expensive overhead of traditional payment networks.
This move suggests a growing recognition that the future of payments may require completely new infrastructure, optimized for the unique demands of autonomous agents.
Consider how a new payment protocol might work in practice. An “Agent Payment Protocol” (APP) could include:
Delegation chain verification – a cryptographic proof chain showing the agent’s authorization to make specific types of purchases
Reference to specific user preferences/rules that were satisfied
Confidence score for the decision
Category-specific limits (e.g., $200 for groceries, $50 for entertainment)
Merchant-specific trust scores
Required human confirmation above certain thresholds
Smart spending controls with programmable constraints like:
Major payment providers could implement this through extensions to existing standards. For instance, Visa’s existing 3D Secure protocol could add an agent verification layer, while Stripe’s API could introduce new parameters for agent-specific transaction metadata.
While payment infrastructure provides the foundation for agent-driven commerce, the very nature of how we complete transactions must also evolve. The familiar checkout process—a hallmark of e-commerce for decades—is about to undergo its own transformation.
Redefined checkout experience
In an agent-first environment, the concept of a traditional checkout—where a human user confirms their purchase by clicking a “Buy” button—fades into the background.
Instead, agents operate with predefined goals and parameters, continuously evaluating whether a proposed transaction aligns with those objectives. Rather than halting everything at a payment prompt, agents could integrate a “stop and reflect” step into their workflows.
For example, if a user’s agent is tasked with booking a flight seat that’s both a window seat and close to an exit, the agent pauses before completing the reservation. It double-checks that the seat assignment matches the user’s criteria and only then proceeds, ensuring flawless execution of the user’s intent and mitigating the probability of the agent going off the rails due to hallucinations.
Stripe perfected its checkout experience with its Optimized Checkout Suite, which dynamically shows customers the most relevant payment methods using machine learning, leading to a 10.5% increase in revenue
This reflective process transforms the final authorization into a subtle verification loop rather than a jarring user interruption. The agent reviews the selected attributes—price, seat location, baggage allowance, and cancellation policy—and compares them against the user’s stored preferences and constraints.
It confirms not only that the requested outcome has been met but also that it falls within acceptable spending limits and trust parameters. This transforms purchasing from a manual “Are you sure?” prompt into a nuanced, data-driven decision matrix.
As these agent-mediated transactions proliferate, payment providers and merchants might offer additional layers of context-aware validation. For instance, when an agent chooses a specific insurance add-on, the payment system could prompt the agent to confirm whether its logic correctly interpreted the user’s needs.
This transparent chain of reasoning, visible to the agent and logged for future reference, ensures that each transaction stands up to scrutiny. Ultimately, the checkout step evolves from a user-facing choke point to an agent-managed quality control measure, minimizing errors and elevating the overall integrity of automated commerce.
As agents reshape how we complete purchases, they’re also forcing us to rethink how businesses attract and engage customers in the first place. The era of human-centric marketing campaigns is giving way to something far more systematic and efficient.
Agent-driven marketing and promotions
Marketing campaigns and promotions will evolve radically in an AI agent-mediated economy.
Traditional email marketing and coupon distribution systems, designed around human attention and impulse, will give way to programmatic offer networks where consumers’ AI agents maintain persistent queries about their principals’ needs and preferences. These agents subscribe to vendor APIs that broadcast real-time offers matching specific criteria, enabling hyper-personalized deal discovery that transcends the limitations of batch email campaigns.
Vendors might maintain agent-first promotional channels that communicate in structured data formats, allowing instant price comparison and benefit analysis. This ecosystem could enable “intent casting”, where agents broadcast shopping goals to trusted vendor networks, receiving precisely targeted offers that align with the principal’s timing, budget, and preferences—all without cluttering a human inbox or requiring manual coupon management.
Consider a practical example: A user instructs their agent to monitor high-end fashion retailers for specific items within their style preferences and budget constraints. Rather than the user repeatedly checking websites or subscribing to countless email lists, their agent maintains persistent monitoring across multiple vendors:
Real-time inventory tracking across size, color, and style variations
Dynamic price monitoring, including flash sales and member-exclusive discounts
Evaluation of shipping times and costs to the user’s location
When ideal conditions align—perhaps a preferred sweater hits the target price point during an end-of-season sale—the agent can either notify the user or execute the purchase automatically based on pre-authorized parameters. This transforms shopping from an attention-demanding activity into an efficient background process governed by clear rules and preferences.
Major retailers like Nordstrom or ASOS could expose agent-specific APIs that provide structured access to:
Real-time inventory and pricing data
Detailed product specifications and measurements
Membership program benefits and restrictions
Regional availability and shipping constraints
This evolution democratizes personal shopping, allowing everyone to benefit from persistent, intelligent monitoring of their fashion preferences, not just those who can afford human personal shoppers. It also enables retailers to better match inventory with actual customer intent, reducing overhead from unsold merchandise and improving supply chain efficiency.
Other companies like Honey may need to pivot to offer agent-optimized tools that integrate directly with vendor APIs, allowing agents to query real-time discounts and rewards. Similarly, Mailchimp and HubSpot could develop agent-oriented campaign frameworks that distribute offers as structured data streams rather than traditional email blasts, ensuring seamless integration with agent-driven workflows.
Agent-native customer support
Customer support today centers on human interactions or user-facing chatbots. In an agent-first paradigm, this shifts to agent-to-agent communication. Personalized AI agents will directly engage with business systems to resolve issues, retrieve shipping or refund policies, or autonomously initiate returns. This evolution will streamline processes, reduce human intervention, and enhance efficiency in support workflows.
In an agent-first paradigm, customer support is no longer solely about human users contacting businesses through chat widgets or call centers. Instead, autonomous agents interact directly with enterprise systems, pulling diagnostic information, requesting refunds, or escalating complex issues to a more constrained/expensive resource like a human or a superior model (e.g., o1 over GPT-4o).
This shift encourages platforms like Intercom to develop agent-oriented communication layers—specialized APIs that allow autonomous agents to navigate support options, retrieve knowledge base articles, and submit detailed troubleshooting requests without human intervention.
These agent-facing APIs would streamline issue resolution, allowing routine queries, such as package tracking, account verification, or policy clarifications, to be handled agent-to-agent, drastically reducing response times.
As soon as a problem arises, the user’s agent can pinpoint the issue and connect with the business’s support agent (be it a specialized LLM or a human representative), negotiating resolutions or applying discounts as needed. The result is a fluid, automated dialogue that bypasses human frustration and latency.
Over time, companies could implement reputation scoring systems that measure how efficiently their support agents (both human and AI) interact with consumer agents. Metrics like resolution speed, policy clarity, and refund accuracy become machine-readable signals, informing user agents which vendors offer superior support experiences.
As more vendors embrace these standards, the entire support ecosystem evolves: prompt, well-structured responses become the norm, and agent-native customer support becomes a hallmark of high-quality digital services.
Imagine a complex warranty claim scenario: Your agent detects that your new laptop’s battery is degrading unusually fast. It immediately:
Collects diagnostic data and usage patterns
Cross-references warranty terms with actual performance
Initiates a support interaction with the manufacturer’s agent
Negotiates a resolution based on precedent cases
Arranges shipping for replacement parts or full device replacement
Schedules a technician visit if needed
This entire process happens without human intervention unless exceptional circumstances arise. The interaction generates a complete audit trail, including all diagnostic data, communication logs, and decision points—valuable data for improving both product quality and support processes.
One example in this space of agentic customer support is Sierra, a startup taking aim at the expansive market of customer support by embedding AI agents into business workflows.
Their conversational agents handle complex queries with contextual precision, managing tasks such as processing returns or updating subscriptions. While their primary focus remains on serving human customers, the foundation they’ve built is clearly aligned with an AI agent-driven future.
With access to company policies (e.g., refund and shipping rules) and robust conversational AI infrastructure (spanning LLMs and voice interfaces), Sierra is well-positioned to seamlessly transition to support agent-to-agent interactions as demand evolves.
Sierra’s agents resolve support tickets autonomously, with Sierra customers only paying for resolved tickets
The end of language-optimized interfaces
As AI agents seamlessly translate and interpret information on the fly, the need for painstakingly maintained multilingual websites diminishes. Instead of forcing businesses to host separate English, French, or Mandarin versions of their interfaces, agents handle language conversion dynamically.
This capability allows brands to maintain a single, streamlined codebase while ensuring that users, regardless of location, receive content and instructions in their preferred language, instantly and accurately.
Website builders like Webflow and Wix could evolve into platforms that generate “universal templates” optimized for agent interpretation rather than human linguistic preferences. Instead of focusing on localized landing pages, these platforms would produce standardized, machine-readable structures enriched with metadata and semantic cues.
Agents, armed with cutting-edge language models, would then adapt the presentation layer for each user, including local dialects, cultural nuances, and even personalization cues drawn from the user’s profile.
The transformation goes beyond simple translation. Agents will handle complex cultural adaptations across multiple dimensions simultaneously. They’ll dynamically adjust pricing strategies for different markets while modifying product descriptions to reflect local preferences and purchasing patterns.
These agents will intelligently adapt imagery and design elements to ensure cultural appropriateness, automatically managing regional compliance requirements such as privacy policies or consumer protection disclosures. They’ll even personalize communication styles based on cultural norms, shifting between formal and casual tones and adapting messaging cadence to match local expectations.
This comprehensive cultural intelligence transforms what was once a labor-intensive localization process into a fluid, automated system that maintains cultural authenticity across all customer touchpoints.
In this new reality, the value proposition of website builders shifts from localization to robustness, structure, and data integrity. Rather than wrestling with manual translations or commissioning multiple language variants, businesses can rely on well-defined data schemas and agent-ready manifests. As a result, the concept of “language-optimized” sites becomes obsolete, replaced by fluid, dynamic interfaces that transcend linguistic barriers.
Small vs. large business impact
This transition creates both opportunities and challenges across the business spectrum. Large enterprises can invest in building sophisticated agent interfaces and maintaining complex agent-ready APIs. However, small businesses might initially struggle with the technical requirements and infrastructure costs.
To bridge this gap, we will likely see the emergence of “agent-enablement platforms”, services that help small businesses become agent-ready without significant technical investment.
Think of them as the Shopify of the agent era, providing standardized tools that level the playing field. These platforms would offer pre-built solutions for creating agent-readable product catalogs and managing automated pricing and inventory systems.
They would include standardized support protocols that small businesses can easily implement, along with simplified integration paths to agent payment systems. By democratizing access to agent-ready commerce capabilities, these platforms will play a crucial role in preventing a digital divide between large and small businesses in the agent economy.
This democratization of agent-ready commerce will be crucial for preventing a digital divide between large and small businesses in the agent economy.
The great rewiring
The transition to an agent-first internet represents more than just a technological shift—it’s a fundamental reimagining of how commerce functions in the digital age. We’re moving from a web optimized for human attention and interaction to one built for efficient, automated decision-making. This transformation touches every aspect of online business:
Payment systems evolve from human-verification models to agent-oriented protocols with built-in delegation and accountability
Marketing shifts from attention-grabbing campaigns to structured, machine-readable offer networks
Customer support transforms from human-to-human interaction to efficient agent-to-agent problem resolution
Language barriers dissolve as agent-mediated communication enables seamless global commerce
Companies that quickly adapt to this new paradigm—implementing agent passports, embracing agent-to-agent protocols, and restructuring their services for machine readability—will shape the next era of online interaction.
Just as the mobile revolution created trillion-dollar opportunities, the agent revolution opens new horizons for innovation and value creation. The businesses that thrive won’t just be those with the best products or prices, but those that best enable and embrace agent-driven commerce.
As productivity software evolves, the role of enterprise IT admins has become increasingly challenging.
Not only are they responsible for enabling employees to use these tools effectively, but they are also tasked with justifying costs, ensuring data security, and maintaining operational efficiency.
In my previous role as a Reporting and Analytics Product Manager, I collaborated with enterprise IT admins to understand their struggles and design solutions. This article explores the traditional pain points of admin reporting and highlights how AI-powered tools are revolutionizing this domain.
Key pain points in admin reporting
Through my research and engagement with enterprise IT admins, several recurring challenges surfaced:
Manual, time-intensive processes: Admins often spent significant time collecting, aggregating, and validating data from fragmented sources. These manual tasks not only left little room for strategic planning but also led to frequent errors.
Data complexity and compliance: The explosion of data, coupled with stringent regulatory requirements (e.g., GDPR, HIPAA), made ensuring data integrity and security a daunting task for many admins.
Unpredictable user requests: Last-minute requests or emergent issues from end-users often disrupted admin workflows, adding stress and complexity to their already demanding roles.
Limited insights for decision-making: Traditional reporting frameworks offered static, retrospective metrics with minimal foresight or actionable insights for proactive decision-making.
To address these pain points, I developed a workflow that automates data collection and improves overall reporting efficiency. Below is a comparison of traditional reporting workflows and an improved, AI-driven approach:
Traditional workflow:
Data collection: Manually gathering data from different sources (e.g., logs, servers, cloud platforms).
Data aggregation: Combining data into a report manually, often using Excel or custom scripts.
Validation: Ensuring the accuracy and consistency of aggregated data.
Report generation: Compiling and formatting the final report for stakeholders.
Improved workflow (AI-driven):
Automation: Introducing AI tools to automate data collection, aggregation, and validation, which significantly reduces manual efforts and errors.
Real-Time Insights: Integrating real-time data sources to provide up-to-date, actionable insights.
Customization: Providing interactive dashboards for on-demand reporting, enabling admins to track key metrics and make data-driven decisions efficiently.
Evolution with AI capabilities: Market research insights
Several leading companies have successfully implemented AI to transform their admin reporting processes. Below are examples that highlight the future of admin reporting:
Microsoft 365 Copilot
Microsoft’s AI-powered Copilot integrates with its suite of apps to provide real-time data insights, trend forecasting, and interactive visualizations.
This proactive approach helps IT admins make data-driven decisions while automating manual processes. By forecasting trends and generating real-time reports, Copilot allows admins to manage resources and workloads more effectively.
Salesforce Einstein Analytics
Salesforce Einstein leverages advanced AI for predictive modeling, customer segmentation, and enhanced analytics.
Admins can forecast future trends based on historical data and create personalized reports that directly impact strategic decision-making. This enables actionable insights that were previously difficult to uncover manually.
Box AI agents
Box’s AI agents autonomously collect, analyze, and report data. These agents detect anomalies and generate detailed reports, freeing admins to focus on higher-priority tasks. By automating complex reporting processes, Box’s AI agents enhance both speed and accuracy in decision-making.
Looking ahead, several emerging capabilities can further unlock the potential of admin reporting:
Seamless data integration: AI-powered tools enable organizations to unify data from disparate systems (e.g., cloud storage, internal databases, third-party applications), providing a holistic view of critical metrics and eliminating the need for manual consolidation.
AI-powered decision support: Context-aware AI can offer personalized recommendations or automate complex workflows based on historical patterns and operational context, reducing manual intervention while enhancing accuracy.
Automated compliance checks: AI tools can continuously monitor compliance with evolving regulations, automatically generating compliance reports to keep organizations secure and up-to-date.
Security and performance monitoring: AI can detect unusual patterns in data, such as unexpected traffic spikes or system anomalies, allowing admins to proactively address potential security threats or failures before they escalate.
Interactive dashboards and NLP: By incorporating natural language processing (NLP), AI tools enable admins to query data using plain language and receive intuitive, visual reports, streamlining analysis and enhancing user experience and usability.
Conclusion
The transformation of admin reporting from manual workflows to AI-driven insights has revolutionized IT operations. By automating routine tasks, delivering real-time insights, and enhancing predictive capabilities, AI empowers IT admins to focus on strategic initiatives while ensuring data accuracy and compliance.
As organizations continue to adopt advanced AI capabilities, the future of admin reporting holds exciting possibilities, from seamless data integration to adaptive, context-aware decision-making tools.
These innovations will not only enhance efficiency but also enable organizations to thrive in an increasingly complex, data-driven world.
The session from Srinath Godavarthi, Director, Divisional Architect at Capital One, focuses on enhancing outcomes for customers and businesses by optimizing generative AI’s performance and output quality.
It highlights the importance of foundation models, their challenges, and the variability in output quality, including issues like hallucinations caused by noisy training data.
The discussion covers four main strategies for improving model performance: prompt engineering, retrieval-augmented generation (RAG), fine-tuning, and building models from scratch.
Each method has its advantages, with prompt engineering offering quick improvements and fine-tuning providing specialized adaptations for specific tasks. Ultimately, the choice of strategy depends on the use case and the complexity involved.
Want to see more?
Become a Pro member today and get access to all sessions from Generative AI Summit Washington, alongside our entire world series.
That’s hundreds of hours of insights straight from some of the world’s top AI leaders.
AI is emerging as a key differentiator in enterprise finance. As traditional financial models struggle to keep up with the pace of change, enterprise tech organizations are turning to AI to unlock faster, more accurate, and insight-driven decision-making.
Drawing from my experience in sales planning and forecasting in the enterprise tech sector, I’ve seen firsthand how AI is reshaping how global enterprises forecast revenue, optimize GTM strategies, and manage P&L risk.
This article explores how AI is transforming financial modeling and sales forecasting (two pillars of enterprise strategy) and helping finance teams shift from reactive to proactive operations.
1. Why traditional forecasting falls short
There are three main reasons why traditional forecasting is falling short:
Lack of broader business context
Sales forecasters and financial modelers frequently lack visibility into wider organizational shifts such as changes in product strategy, marketing campaigns, or operational execution that affect demand and performance. This makes it difficult to fine-tune models for niche business dynamics or rapidly changing market conditions.
Inflexibility
They often have an inability to account for real-time changes in demand, market shifts, economic conditions, tariffs, or sales performance.
Human bias
Over-reliance on gut-feel projections leads to inaccurate financial planning.
In many enterprise settings, these limitations create friction between planning and execution across business functions, finance, sales, and marketing. Misaligned forecasts result in delayed strategic actions and misused resources, which are issues that AI is now well-positioned to solve.
2. What makes AI a game-changer for financial modeling
Cross-functional simulations tailored by domain experts
One of AI’s most transformative strengths lies in its ability to empower every function within the enterprise to personalize simulations using their domain-specific expertise. For example:
The pricing team can continuously adjust models based on real-time strategy updates.
The product team can simulate outcomes tied to roadmap changes or launch timing.
The marketing team can incorporate variable lead generation budgets or campaign performance assumptions.
Likewise, GTM leaders can simulate how scaling inside sales headcount could drive more transactional business and enhance margins. These deeply integrated, cross-functional simulations not only improve forecast precision but also drive strategic alignment and execution agility across the business.
Real-time forecast adjustments
Unlike static quarterly models, AI allows finance leaders to refresh forecasts dynamically, giving real-time visibility into revenue performance. This is particularly useful in fast-evolving segments like AI infrastructure, where product cycles and demand signals change rapidly.
AI can streamline pipeline visibility and improve forecast reliability through:
Collaborative pipeline reviews with finance and sales using AI-generated risk scores and close probabilities.
Analysis of competitor dynamics and market share shifts at the product and geo level to understand how winning or losing specific deals affects strategic positioning.
Enhanced understanding of how pipeline outcomes impact both profitability and long-term growth trajectories.
Improved sales productivity
AI boosts front-line efficiency by guiding sales teams to focus efforts on the right product segments expected to experience a surge in demand (such as those driven by OS refresh cycles, compliance deadlines, or emerging industry triggers), enabling them to strategically capture growth opportunities.
AI also helps to prioritize accounts while providing accurate bundling suggestions based on buyer profiles and sales history to increase deal size and win rates.
Tighter finance-sales alignment
AI serves as a bridge between strategic planning and operational execution by:
Providing shared insights to drive collaboration between FP&A, GTM, and sales teams.
Enabling joint decision-making based on real-time financial and sales data.
Improving coordination between business units through unified performance metrics.
Reducing misalignment and strategic blind spots across planning cycles.
5. Key considerations for implementation
Data readiness: Clean, structured data is critical. Integrating CRM, ERP, and planning systems improves AI effectiveness.
Human oversight: AI augments, not replaces, finance leadership. Human intuition is still key for context and judgment.
Change management: Teams need training and adoption support to fully leverage AI’s potential.
Conclusion
AI is redefining how enterprise tech companies forecast, plan, and execute. From lead targeting to revenue modeling and cross-functional scenario planning, it brings precision, agility, and alignment to financial operations.
By breaking silos and enabling real-time collaboration across finance, GTM, and sales, AI turns forecasting into a growth engine. Companies that embed AI into their processes will be better positioned to anticipate market shifts, improve profitability, and lead with confidence.
*Disclaimer: The views expressed in this article are my own and do not reflect the official policy or position of any organization. *
This article comes from Dr Nikolay Burlutskiy’s talk at our London 2024 Generative AI Summit. Check out his full presentation and the wealth of OnDemand resources waiting for you.
Nikolay is currently the Senior Manager of GenAI Platforms at Mars
Have you ever wondered just how long it takes to bring a new medicine to market? For those of us working in the pharmaceutical industry, the answer is clear: it can take decades and cost billions. As a computer scientist leading the AI team at AstraZeneca, I’ve seen firsthand just how complicated the drug discovery process is.
Trust me, there’s a lot of work that goes into developing a drug. But the real challenge lies in making the process more efficient and accessible, which is where generative AI comes in.
In this article, I’ll walk you through the critical role that AI plays in accelerating drug discovery, particularly in areas like medical imaging, predicting patient outcomes, and creating synthetic data to address data scarcity. While AI has incredible potential, it’s not without its challenges. From building trust with pathologists to navigating regulatory requirements, there’s a lot to consider.
So, let’s dive into how AI is reshaping the way we approach drug discovery and development – and why it matters to the future of healthcare.
Generative AI’s role in enhancing medical imaging
One of the most powerful applications of generative AI in drug development is its ability to analyze medical images – a process that’s essential for diagnosing diseases like cancer, which can be difficult to detect early on.
In the world of pathology, we’re increasingly moving away from using traditional microscopes, and using digital images instead. With digitized tissue biopsies, we now have access to incredibly detailed scans that show every single cell. The sheer volume of this data – sometimes containing over 100,000 x 100,000 pixels – makes it almost impossible for human pathologists to analyze every single detail, but AI can handle this level of complexity.
At AstraZeneca, we’ve been using generative AI to help analyze these vast datasets. One of the most exciting developments is in medical imaging, where AI models can quickly identify cancerous cells, segment different areas of tissue, and even predict patient outcomes.
For example, AI can help predict whether a patient will respond to a specific drug – information that’s invaluable for companies like ours, as we work to develop treatments that will provide real, tangible benefits for patients.
In my work, we leverage powerful AI techniques such as variational autoencoders and generative adversarial networks (GANs) to build these models. These AI techniques can help us learn from medical images and generate synthetic data that can be used to train AI models more effectively.
The secret? Agent passports: cryptographic credentials that prove delegation, set spending limits, and unlock seamless agent-to-agent coordination.
We’re entering the agent-first internet, where human-era systems (CAPTCHAs, review sites, IP throttling) break down, and new infrastructure rises to support fully autonomous assistants.
What’s changing?
Identity: agents verify delegation, not humanity
Privacy: agents manage granular data permissions in real time
Trust: star ratings are out, verifiable metrics are in
Security: new attack surfaces, new protections
The takeaway? The next internet runs on agents. And whoever builds the infrastructure? Wins.
Meet Gemini 2.5 Flash: Fast, smart, and fully tunable
Google just dropped Gemini 2.5 Flash. An accelerated, cost-efficient model with a twist: you control how much it thinks.
It’s the first hybrid reasoning model:
Turn thinking on/off depending on your use case
Set a thinking budget to balance speed, quality, and cost
Keep Flash-fast responses with smarter performance
Even with reasoning disabled, 2.5 Flash outperforms its predecessor and crushes the price-to-performance curve.
Need deep logic for tough prompts? Crank up the budget.
Just want speed? Set it to zero. Either way, you’re in control.
The takeaway? Fast is table stakes. Controllable reasoning is the future.
Top AI Accelerator Institute resources
1. Today (April 24), discover how prompt injection attacks are putting generative AI at risk and the defenses you need to stay ahead in our live session, Words as Weapons. 2. How to balance helpfulness and harmlessness in AI 3. AWS, Anthropic, and Glean unpack how enterprises can scale AI smartly with agentic tech, rock-solid security, and real ROI on May 6
AIOps in action: AI & automation transforming IT operations
Traditional IT ops are slow, reactive, and overloaded.
How to 8‑bit quantize large models using bits and bytes
Massive models, massive problems: until you quantize.
8-bit quantization shrinks model size, reduces memory usage, and boosts speed, all with minimal loss of accuracy.
Here’s what it unlocks:
75 percent memory savings
Faster inference on CPUs, GPUs, edge devices
Energy-efficient deployment
No major code changes with tools like BitsAndBytes
A real-world example is IBM Granite: 2B parameters, now edge-ready with a single config flag.
The takeaway? Quantization is the quiet revolution powering real-world AI.
Added to our Pro and Pro+ membership dashboard this month:
OnDemand: Generative AI Summit Washington, D.C. Generative AI Summit Austin Generative AI Summit Toronto Computer Vision Summit London
Exclusive articles: The truth about enterprise AI agents (and how to get value from them) How to secure LLMs with the fastest guardrails for peak AI performance GenAI creation: Building for cross-platform wearable AI and mobile experiences Building advanced AI systems: Challenges and best practices
You’re currently an Insider member. Upgrade to Pro+ to access all this every month, plus a complimentary in-person ticket, and members’ events.
Reach 2.3 million+ AI professionals
Spread the word about your brand, acquire new customers, and grow revenue.
Engage AIAI’s core audience of engineers, builders, and executives across 25+ countries spanning North America, Asia, and EMEA.











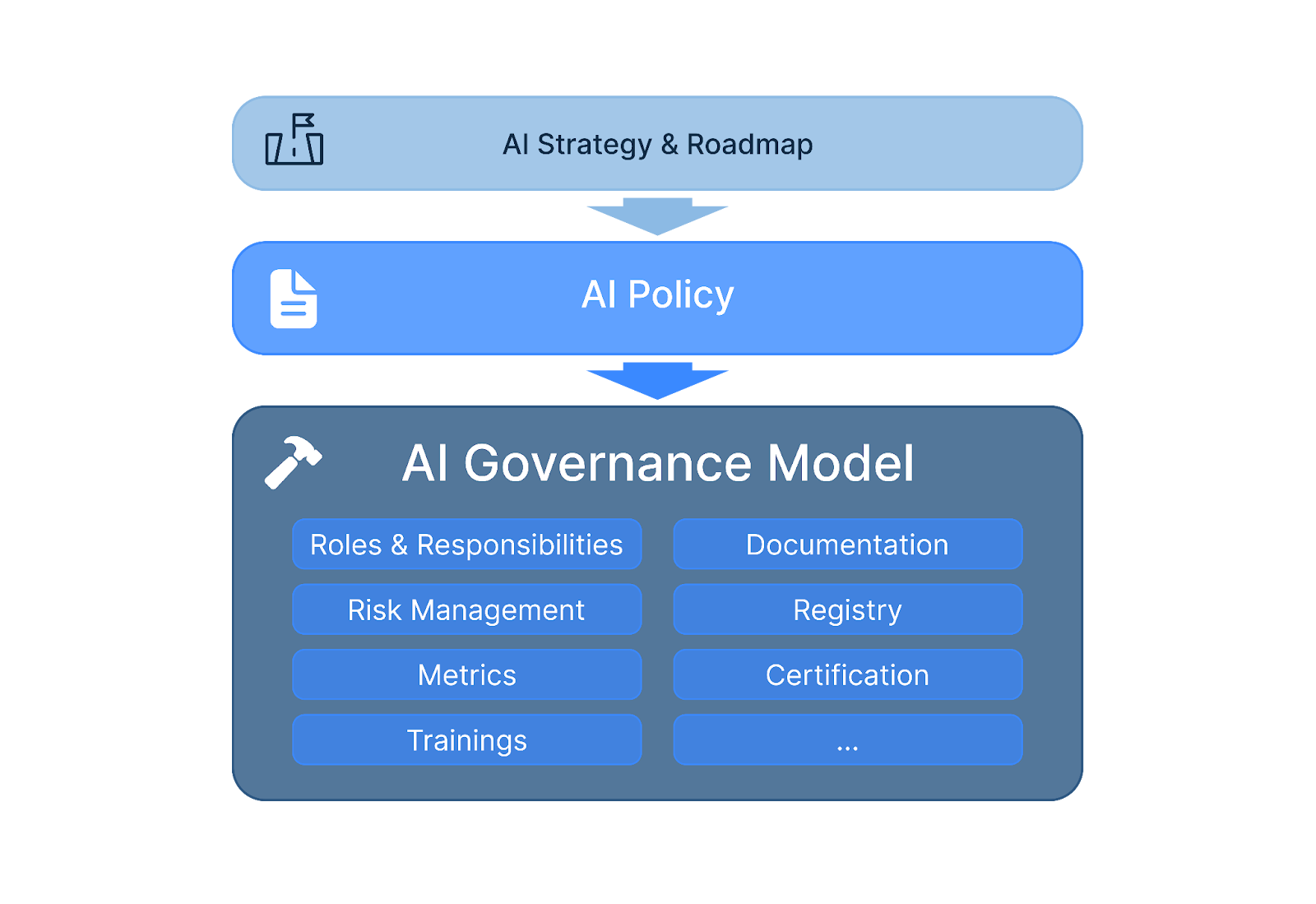
























.mp4 [optimize output image]")








