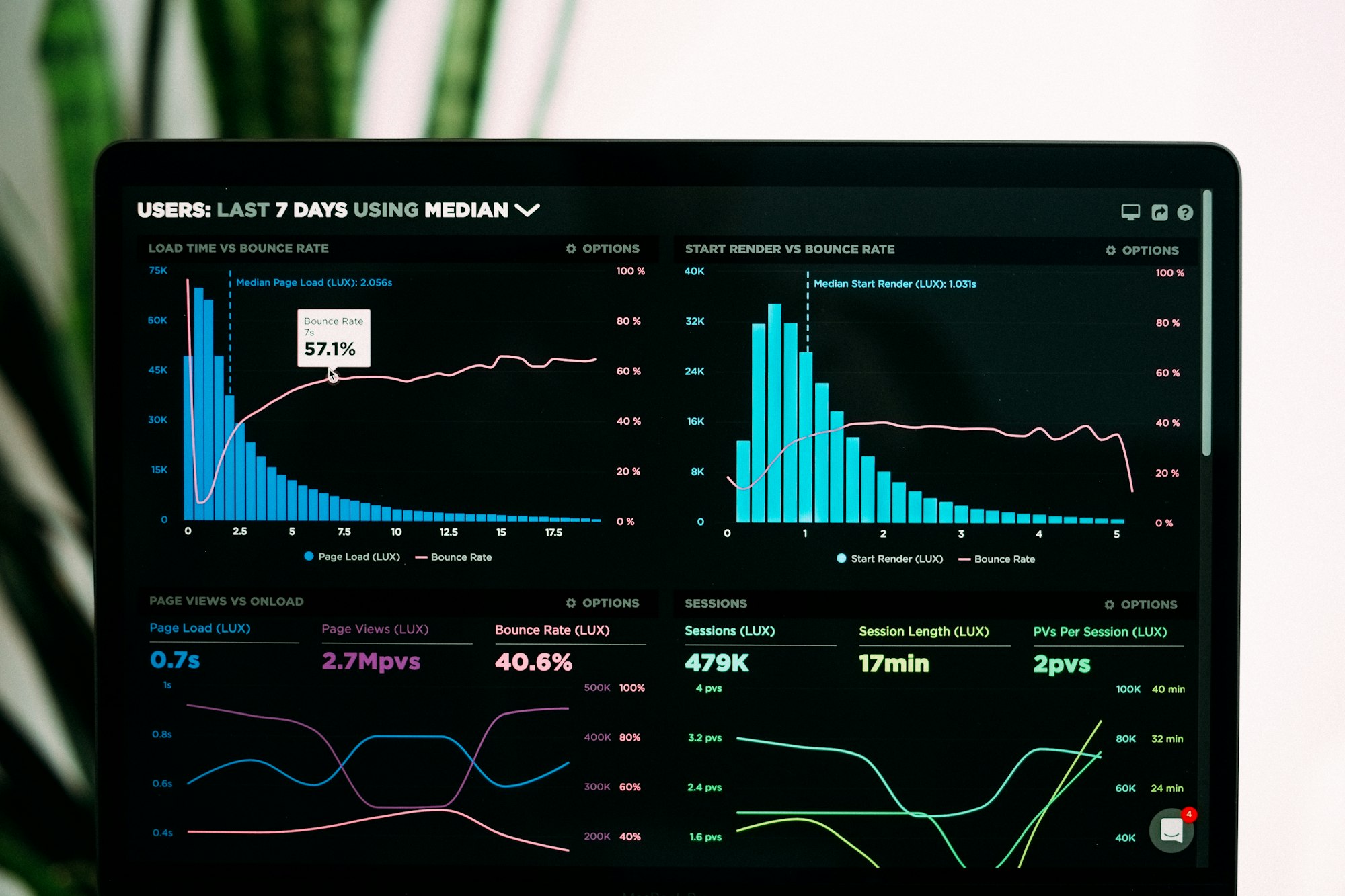
It’s December 2028. Sarah’s AI agent encounters an unusual situation while booking her family’s holiday trip to Japan. The multi-leg journey requires coordinating with three different airlines, two hotels, and a local tour operator.
As the agent begins negotiations, it presents its “agent passport”—a cryptographic attestation of its delegation rights and transaction history. The vendors’ systems instantly verify the agent’s authorization scope, spending limits, and exposed metadata like age and passport number.
Within seconds, the agent has established secure payment channels and begun orchestrating the complex booking sequence. When one airline’s system flags the rapid sequence of international bookings as suspicious, the agent smoothly provides additional verification, demonstrating its legitimate delegation chain back to Sarah.
What would have triggered fraud alerts and CAPTCHA challenges in 2024 now flows seamlessly in an infrastructure built for autonomous AI agents.
—> The future, four years from now.
In my previous essay, we explored how websites and applications must evolve to accommodate AI agents. Now we turn to the deeper infrastructural shifts that make such agent interactions possible.
The systems we’ve relied on for decades: CAPTCHAs, credit card verification, review platforms, and authentication protocols, were all built with human actors in mind. As AI agents transition from experimental curiosities to fully operational assistants, the mechanisms underpinning the digital world for decades are beginning to crack under the pressure of automation.
The transition to an agent-first internet won’t just streamline existing processes—it will unlock entirely new possibilities that were impractical in a human-centric web. Tasks that humans find too tedious or time-consuming become effortless through automation.
Instead of clicking ‘Accept All’ on cookie banners, agents can granularly optimize privacy preferences across thousands of sites. Rather than abandoning a cart due to complex shipping calculations, agents can simultaneously compare multiple courier services and customs implications.
Even seemingly simple tasks like comparing prices across multiple vendors, which humans typically limit to 2-3 sites, can be executed across hundreds of retailers in seconds. Perhaps most importantly, agents can maintain persistent relationships with services, continuously monitoring for price drops, policy changes, or relevant updates that humans would miss.
This shift from manual, limited interactions to automated, comprehensive engagement represents not just a change in speed, but a fundamental expansion of what’s possible online.
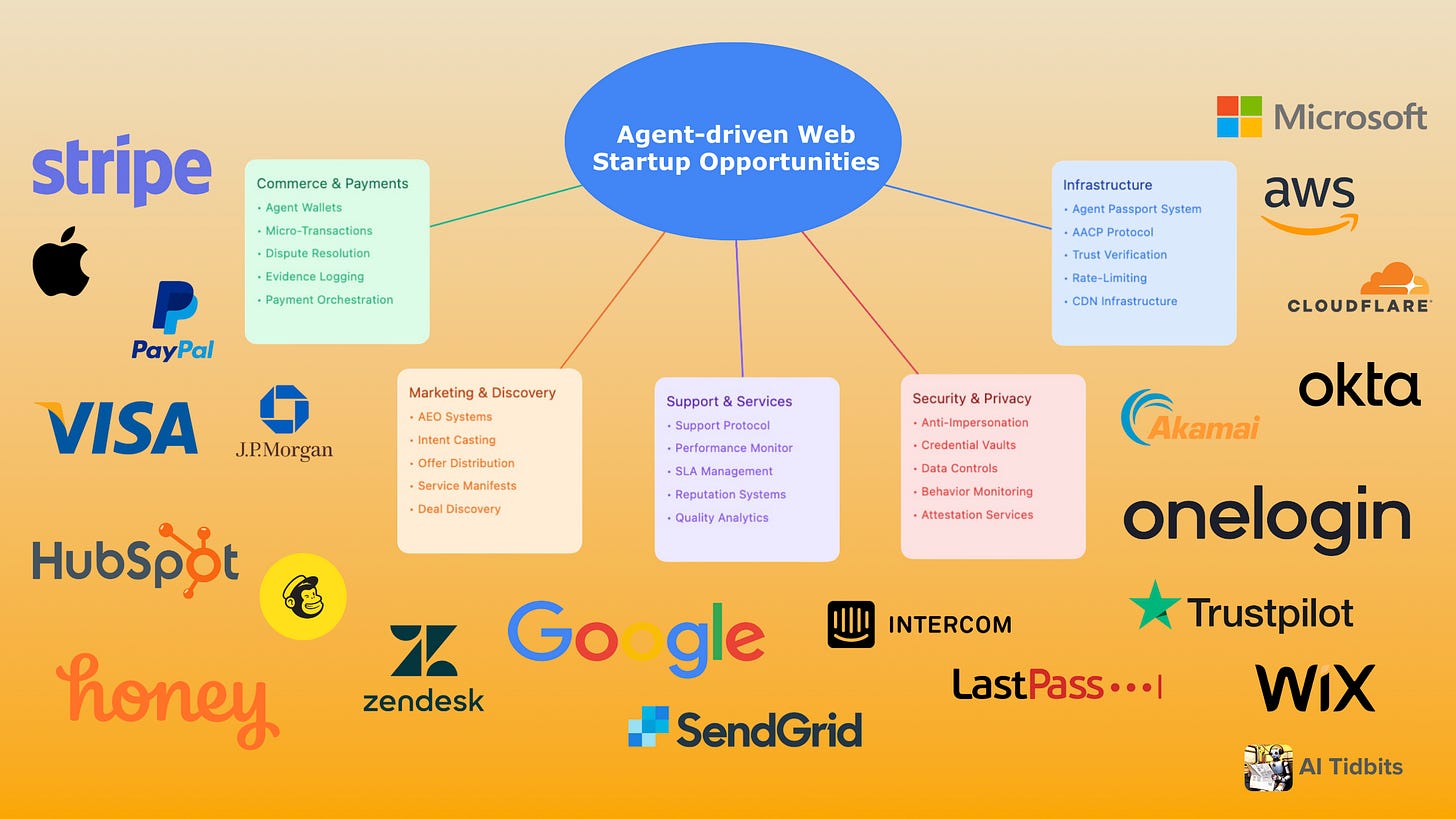
Amid these sweeping changes, a new gold rush is emerging. Just as the shift to mobile created opportunities for companies like Uber and Instagram to reinvent existing services, the transition to agent-first infrastructure opens unprecedented possibilities for founders.
From building next-generation authentication systems and trust protocols to creating agent-mediated data marketplaces, entrepreneurs have a chance to establish the foundational layers of this new paradigm. In many ways, we’re returning to the internet’s early days, where core infrastructure is being reimagined from the ground up—this time for an autonomous, agent-driven future.
In this second post of the AI Agents series, we’ll focus on the foundational infrastructure changes that underlie the agent-first internet: new authentication mechanisms, trust systems, novel security challenges, and agent-to-agent protocols, setting the stage for the more commerce-oriented transformations we’ll explore in the following post.
This article was originally published here at AI Tidbits, where you can read more of Sahar’s fascinating perspectives on AI-related topics.
Proving you’re a human an agent
Remember when “proving you’re not a robot” meant deciphering distorted text or selecting crosswalk images? Those mechanisms become obsolete in a world where legitimate automated actors are the norm rather than the exception.
Today’s CAPTCHAs, designed to block bots, have become increasingly complex due to advances in multimodal AI. Paradoxically, these mechanisms now hinder real humans while sophisticated bots often bypass them. As AI outpaces human problem-solving in these domains, CAPTCHAs risk becoming obsolete, reducing website conversions, and frustrating legitimate users.
The challenge shifts from proving humanity to verifying the agent has been legitimately delegated and authorized by a human user.

Today’s rate-limiting mechanisms assume human-paced interactions, relying heavily on IP-based throttling to manage access. But in a world of AI agents, what constitutes “fair use” of digital services? In an agent-driven internet, automated browsing will become not just accepted but essential. Cloudflare, Akamai, and similar services will need to pivot from simplistic IP-based throttling to sophisticated agent-aware frameworks.
As businesses grapple with these challenges, a new solution is emerging—one that shifts the paradigm from blocking automated traffic to authenticating and managing it intelligently. Enter the Agent Passport.
Imagine a digital credential that encapsulates an agent’s identity and permissions—cryptographically secured and universally recognized. Unlike simple API keys or OAuth tokens, these passports maintain a verifiable chain of trust from the agent back to its human principal. They carry rich metadata about permissions scope, spending limits, and authorized behaviors, allowing services to make nuanced decisions about agent access and capabilities.
By integrating Agent Passports, business websites like airlines can distinguish between legitimate, authorized agents and malicious actors. New metrics, such as agent reliability scores and behavioral analysis, could ensure fair access while mitigating abuse, balancing security with the need to allow agent-driven traffic.
Authentication mechanisms, such as signing up and signing in, must also evolve for an agent-first internet. Websites will need to determine not just an agent’s identity but also its authorized scope—what data the agent is authorized to access (‘read’) and what actions it is permitted to execute (‘write’).

Google Login revolutionized online authentication by centralizing access with a single credential, reducing friction and enhancing security. Similarly, agent passports could create a universal standard for agent authentication, simplifying multi-platform access while maintaining robust authorization controls.
Companies like Auth0 and Okta could adapt by offering agent-specific identity frameworks, enabling seamless integration of these passports into their authentication platforms. Meanwhile, consumer companies like Google and Apple could extend their authentication and wallet services to seamlessly support agent-mediated interactions, bridging the gap between human and agent use cases.
A new protocol for Agent-to-Agent communication
In the early days of the web, protocols like HTTP emerged to standardize how browsers and servers communicated. In much the same way, the rise of agent-mediated interactions demands a new foundational layer: an Agent-to-Agent Communication Protocol (AACP). This protocol would formalize how consumer agents and business agents discover each other’s capabilities, authenticate identities, negotiate trust parameters, and exchange actionable data—all while ensuring both parties operate within well-defined boundaries.
Just as Sarah’s travel agent from the intro paragraph seamlessly coordinated with multiple airlines and hotels, AACP enables complex multi-party interactions that would be tedious or impossible for humans to manage manually.
Much like HTTPS introduced encryption and certificates to authenticate servers and protect user data, AACP would implement cryptographic attestation for agents. Trusted third-party authorities, similar to today’s certificate authorities, would issue digital “agent certificates” confirming an agent’s legitimacy, delegation chain, and operational scope. This ensures that when a consumer’s travel-planning agent communicates with an airline’s booking agent, both sides can instantly verify authenticity and adherence to agreed-upon standards.
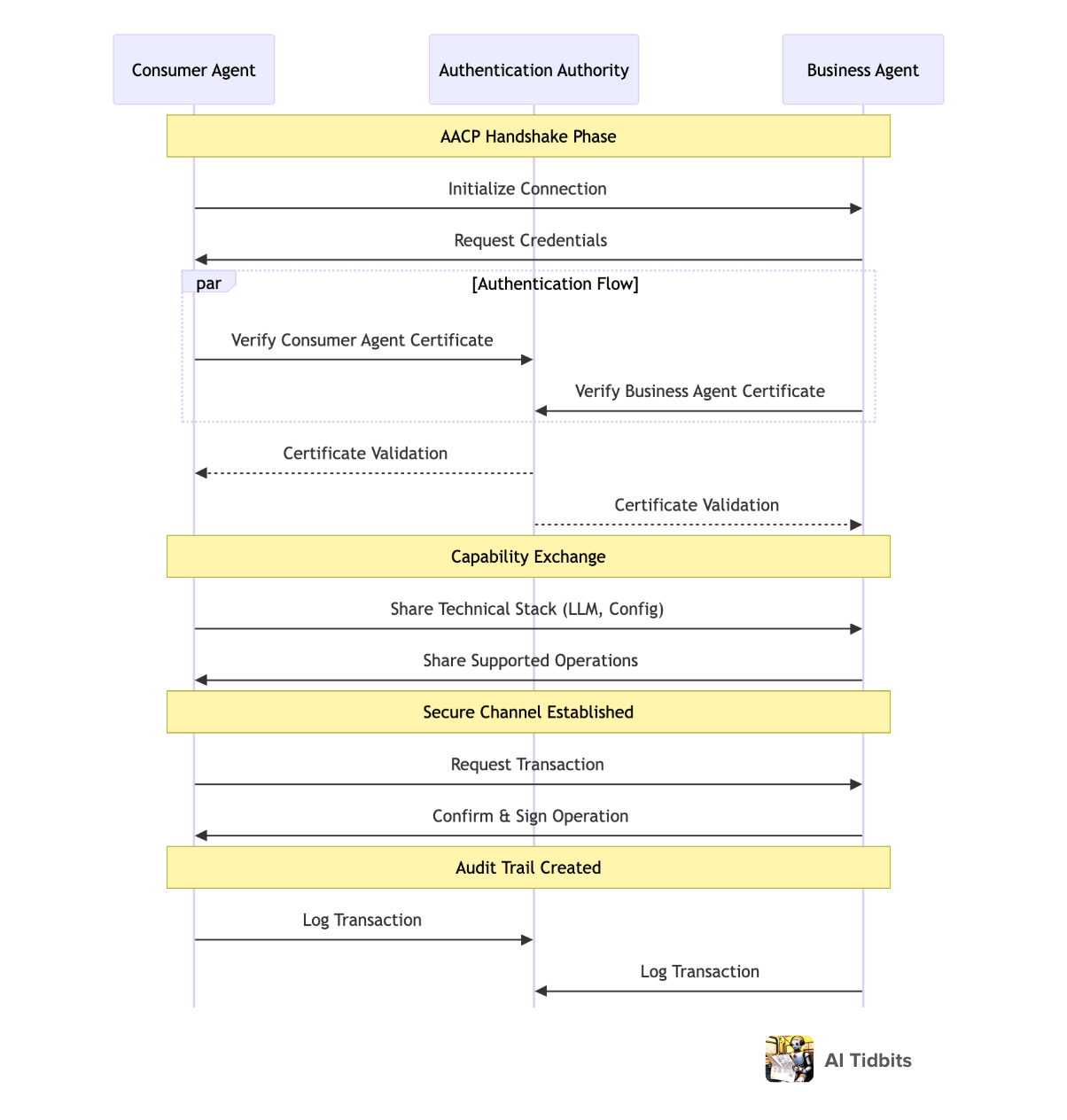
Without such a protocol, a rogue agent might impersonate a trusted retailer to trick consumer agents into unauthorized transactions, or a malicious consumer agent could spoof credentials to overwhelm a merchant’s infrastructure. By mandating cryptographic proof, robust authentication handshakes, and behavior logs, AACP mitigates these threats before meaningful data or funds change hands.
The handshake phase in AACP would include mutual disclosure of the agents’ technical stacks—such as which LLM or language configuration they use—and their supported capabilities. Once established, the protocol would also govern “write-like operations” (e.g., initiating a payment or updating account details) by enforcing strict sign-offs with auditable cryptographic signatures. Every action would leave a verifiable trail of authorization that can be reviewed and validated after the fact.
Finally, AACP would incorporate locale and language negotiation at the protocol level. Although agents can translate and interpret content dynamically, specifying a preferred language or locale upfront helps streamline interactions. This new protocol weaves together trust, authentication, and contextual awareness, forging a resilient substrate on which the agent-first internet can reliably function.
Trust and reputation reimagined
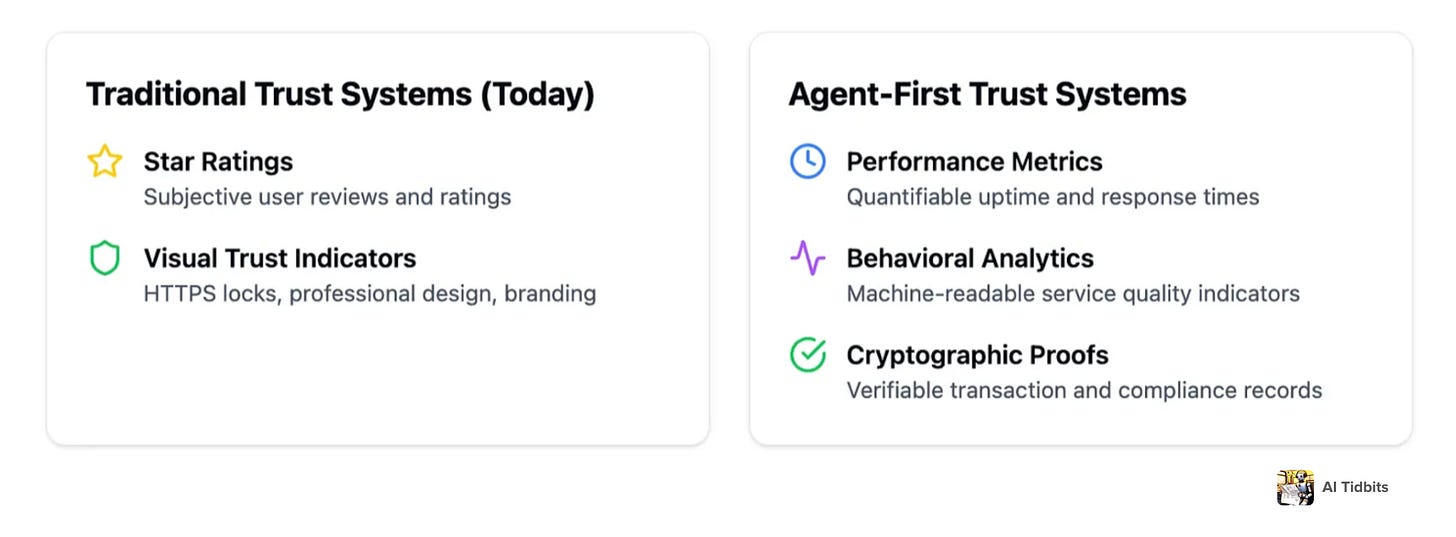
When we navigate the internet, our judgment of a website’s credibility hinges on a blend of visual and social cues. We look for secure HTTPS connections, professional design, and familiar branding to assure us that a site is trustworthy. No one wants to input their credit card information on a site that looks like it was built in the early 2000s. User reviews and star ratings on platforms like Trustpilot and G2 further influence our decisions, offering insights drawn from shared human experiences.
Perhaps no aspect of online commerce requires more fundamental reimagining than trust and reputation systems. In an agent-mediated economy, traditional cues for reliability fall short. AI agents can’t interpret visual aesthetics or branding elements–they operate on data, protocols, and cryptographic proofs.
Trust mechanisms must pivot from human perception to machine-readable verifications. For instance, an agent might verify a seller’s identity through cryptographic attestations and assess service quality via automated compliance records, ensuring decisions are based on objective, tamper-proof data. Traditional review platforms like Trustpilot and G2, built around subjective human experiences and star ratings, will also become increasingly obsolete.
The emerging alternative is a new trust infrastructure built on quantifiable, machine-readable metrics. Instead of relying on potentially AI-generated reviews, a problem that has already undermined traditional review systems, agents could assess services using benchmarks like delivery time reliability, system uptime, or refund processing speed—measurable metrics that ensure objective evaluations rather than subjective human reviews.
This could involve decentralized reputation networks where trust is established through cryptographically verified interaction histories and smart contract execution records. Such systems would offer objective assessments of service quality, enabling agents to make informed decisions without relying on potentially biased or manipulated human reviews.
Moreover, the feedback loop between consumers and businesses will evolve dramatically. Instead of sending generic emails requesting reviews—a method often resulting in low response rates—commerce websites can engage directly with your AI agent to collect timely feedback about specific topics like shipping or product quality.
They might offer incentives like future store credit to encourage participation. The human user could provide a brief impression, such as “The cordless vacuum cleaner works well, but the battery life is short.” The agent then takes this input, contextualizes it with additional product data, and generates a comprehensive review that highlights key features and areas for improvement. This process not only saves time for the user but also provides businesses with richer, more actionable insights.
Trustpilot and G2 could pivot by introducing agent-oriented verification systems, such as machine-readable trust scores derived from operational metrics like service accuracy, delivery consistency, and customer support responsiveness, enabling agents to evaluate businesses programmatically.
The new data-sharing economy
Information sharing in the age of AI agents demands a fundamental reinvention of the current consent and data access model. Rather than blunt instruments like cookie banners and privacy policies, websites will implement structured data requirement protocols—machine-readable manifests that explicitly declare what information is needed and why.
This granular control would operate at multiple levels of specificity. For example, an agent could share your shirt size (L) with a retailer while withholding your exact measurements. It might grant 24-hour access to your travel dates, but permanent access to your seating preferences.
When a service requests location data, your agent could share your city for shipping purposes but withhold your exact address until purchase confirmation. These permissions wouldn’t be just binary yes/no choices—they could include sophisticated rules like “share my phone number only during business hours” or “allow access to purchase history solely for personalization, not marketing.”
Such granular controls, impossible to manage manually at scale, become feasible when delegated to AI agents operating under precise constraints.
AI agents would also act as sophisticated information gatekeepers, maintaining encrypted personal data vaults and negotiating data access in real time.
These mechanisms will fundamentally shift the balance of power in data-sharing dynamics. GDPR-like frameworks may evolve to include provisions for dynamic, agent-mediated consent, allowing for more granular data-sharing agreements tailored to specific tasks.
Websites might implement real-time negotiation protocols, where agents can evaluate and respond to data requests based on their principal’s preferences, preserving privacy while optimizing functionality.
New attack vectors
The shift to agent-mediated interaction introduces novel security challenges. Agent impersonation and jailbreaking agents are two examples.
Jailbreaking AI agents poses significant risks, as manipulated agents could act outside their intended scope, leading to unintended purchases or other errors. Techniques like instruction-tuning poisoning or adversarial suffix manipulation could alter an agent’s behavior during critical tasks.
For example, adversarial instructions embedded in websites’ HTML might influence an agent’s purchasing logic, bypassing its human-defined constraints. Robust safeguards and continuous monitoring will be essential to prevent these vulnerabilities.
Agent impersonation adds a complex layer to cybersecurity challenges. Malicious actors could spoof an agent’s credentials to access sensitive data or execute fraudulent transactions. Addressing this threat demands robust multi-layered verification protocols, such as cryptographic identity verification paired with continuous behavioral monitoring, to ensure authenticity and safeguard sensitive interactions.
Building the new web – opportunities for founders
The web’s agent-first future has no established playbook, and that’s exactly where founders thrive. Entirely new product categories are waiting to be defined: agent-to-agent compliance dashboards, cryptographic attestation services that replace outdated CAPTCHAs, and dynamic data-sharing frameworks that make “privacy by design” a reality.
Platforms that offer standardized “agent passports,” identity brokerages that verify delegation rights, agent-native payment gateways, and trust ecosystems driven by machine-readable performance metrics—each of these represents a greenfield opportunity to set the standards of tomorrow’s internet.
Startups anticipating these shifts can position themselves as foundational players in an agent-driven economy, opening new channels of value creation and establishing a competitive edge before the rest of the market catches up.
Some concrete areas include:
- Trustpilot for agents – creating machine-readable trust metrics and reputation systems that help agents evaluate services and vendors
- Okta for AI agents – building the identity and authentication layer that manages agent credentials, permissions, and delegation chains
- OneTrust for agents – creating the new standard for privacy preference management, turning today’s basic cookie banners into sophisticated data-sharing frameworks where agents can negotiate and manage granular permissions across thousands of services
- Cloudflare for agent traffic – developing intelligent rate-limiting and traffic management systems designed for agent-scale operations
- LastPass for agent permissions – building secure vaults that manage agent credentials and access rights across services
- AWS CloudFront for agent data – creating CDN-like infrastructure optimized for agent-readable formats and rapid agent-to-agent communication
- McAfee security for agents – developing security platforms that protect against agent impersonation and novel attack vectors
Go build.